







Disclaimer: This article is translated by DeepL, there is the original post in Chinese.
Background
Storage is the cornerstone of big data, and metadata of storage system is its core brain. The performance of metadata is very critical to the performance and scalability of the whole big data platform. In this paper, we have selected 3 typical storage solutions for big data platform to test the performance of metadata and have a big competition.
Among them, HDFS is a widely used big data storage solution, which has been precipitated and accumulated for more than ten years and is the most suitable reference benchmark.
The object storage represented by Amazon S3 and Aliyun OSS is also a candidate for big data platform on the cloud, but it only has some of the functions and semantics of HDFS, and the performance is also quite poor, so it is not widely used in practice. In this test object storage is represented by Aliyun OSS, and other object storage is similar.
JuiceFS is a newcomer to the big data scene, built for big data on the cloud, is a big data storage solution in line with the cloud native features. JuiceFS uses object storage on the cloud to save customer data content, through JuiceFS metadata service and Java SDK to achieve full compatibility with HDFS, without any modification to the data analysis components can It is possible to get the same experience as HDFS without any modification to the data analysis component.
Testing Methods
There is a component in Hadoop called NNBench that is designed to crunch the performance of file system metadata, and this article uses it to do so.
The original NNBench has some limitations, and we have made the following adjustments:
- the original NNBench's single test task is single-threaded, which has low resource utilization, we changed it to multi-threaded to facilitate increased concurrency pressure.
- The original NNBench uses hostname as part of the path name, which does not consider the conflict problem of multiple concurrent tasks in the same host, resulting in multiple test tasks repeatedly creating and deleting files, which is not quite in line with the actual situation of big data workload. to avoid conflicts between multiple test tasks on one host.
We used three Aliyun 4-core 16G virtual machines to do the stress test, and CDH 5 is a widely used distribution, HDFS version is 2.6.
HDFS is a highly available configuration with 3 JournalNodes, JuiceFS is a Raft group with 3 nodes, HDFS uses intranet IP, JuiceFS uses elastic IP, HDFS has better network performance.
Data Analysis
Let's look at the performance of the familiar HDFS:
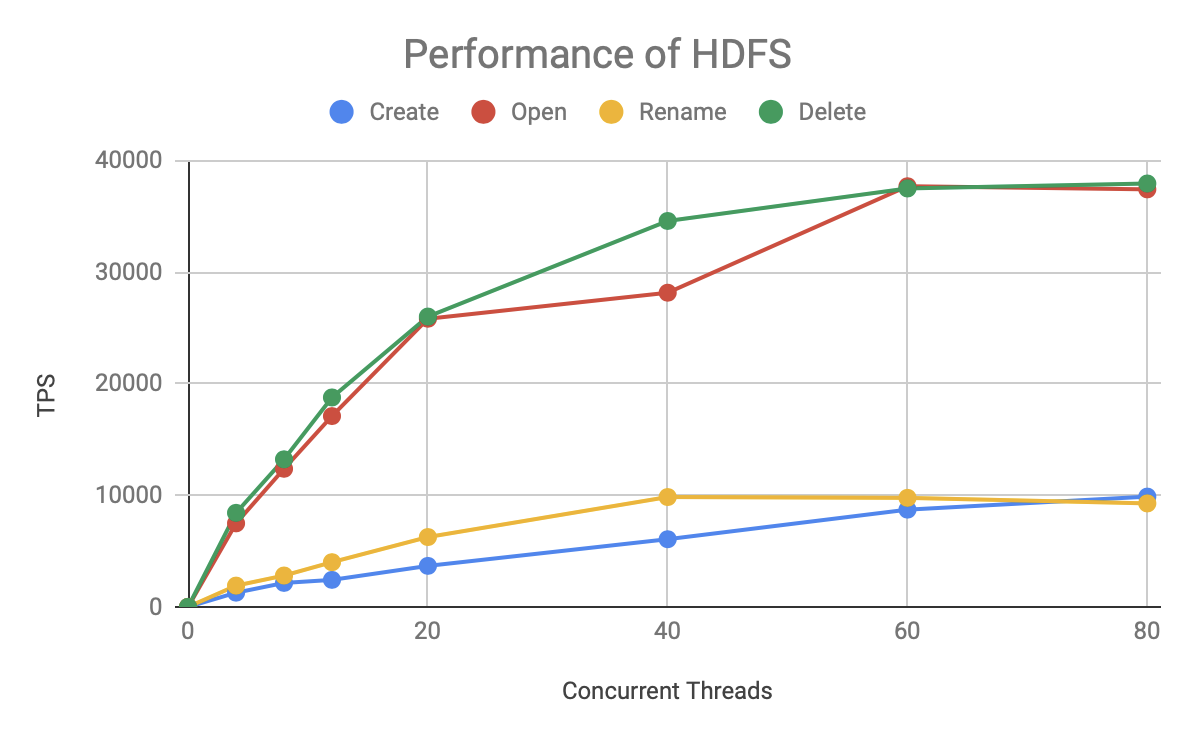
This graph depicts the curve of the number of requests per second (TPS) processed by HDFS as the number of concurrency grows, with two findings.
- The performance of the Open/Read and Delete operations is much higher than that of Create and Rename.
- TPS grows linearly with concurrency until 20 concurrent requests, and then grows slowly until 60 concurrent requests reach the TPS limit (full load).
Let's look at the performance of OSS:
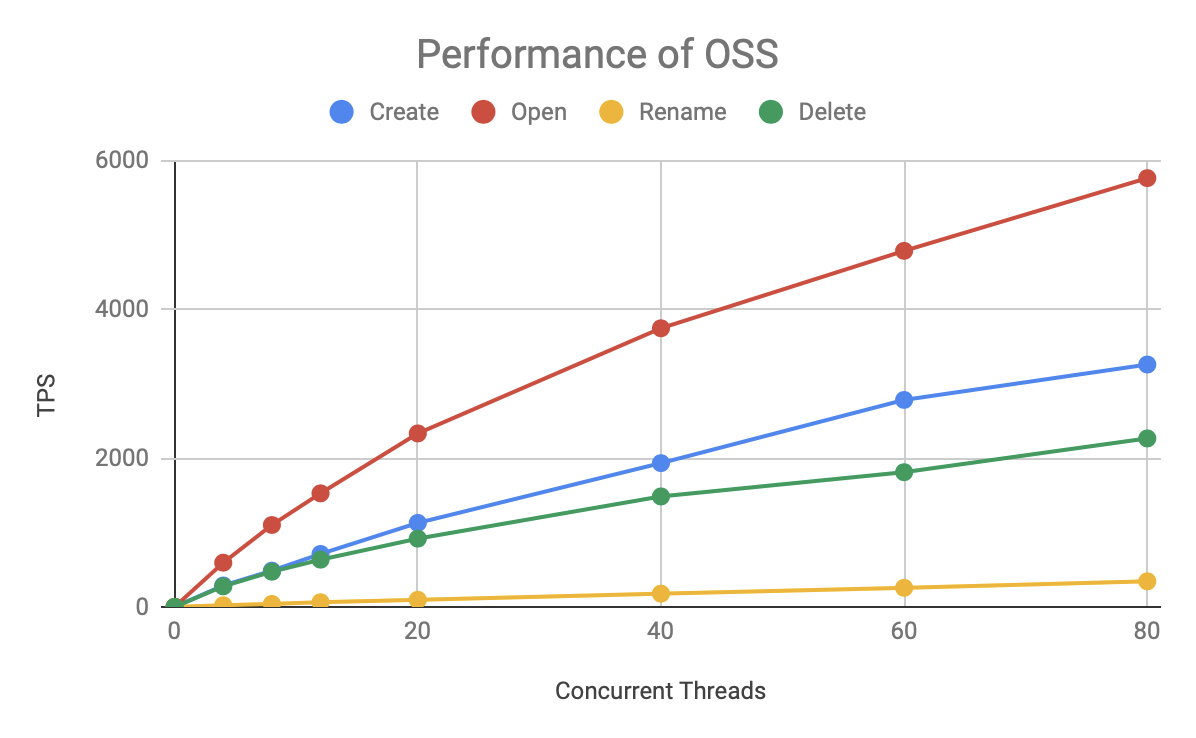
OSS is an order of magnitude slower than HDFS, but its speed for various operations remains largely stable, and the total TPS grows with concurrency, with no bottlenecks yet at 80 concurrent. Due to the limitation of testing resources, we could not further increase the pressure test to know its upper limit.
Finally, look at the performance of JuiceFS:
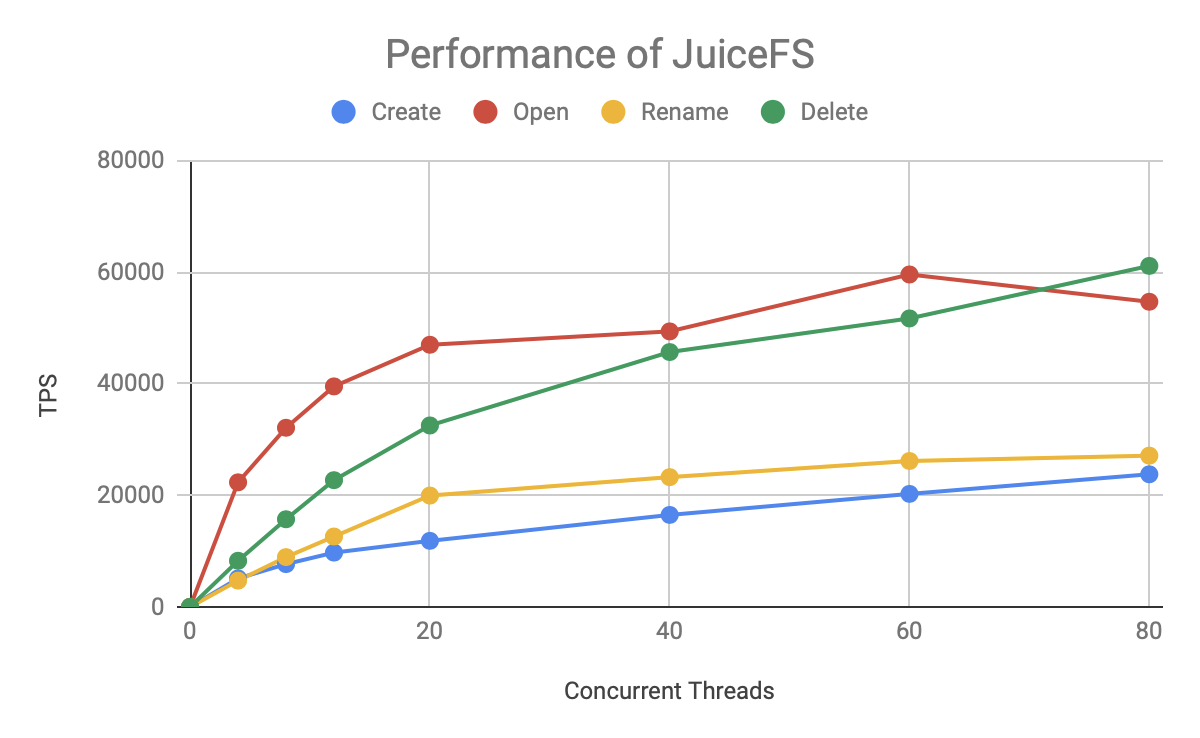
The overall trend is similar to that of HDFS, with Open/Read and Delete operations being significantly faster than Create/Rename. the TPS of JuiceFS also basically keeps thread growth up to 20 concurrent, then slows down and reaches the top line around 60 concurrent. But JuiceFS grows faster and has a higher ceiling.
Detailed performance comparison
To better visualize the performance difference between the three, we directly compare HDFS, Aliyun OSS and JuiceFS together as follows:
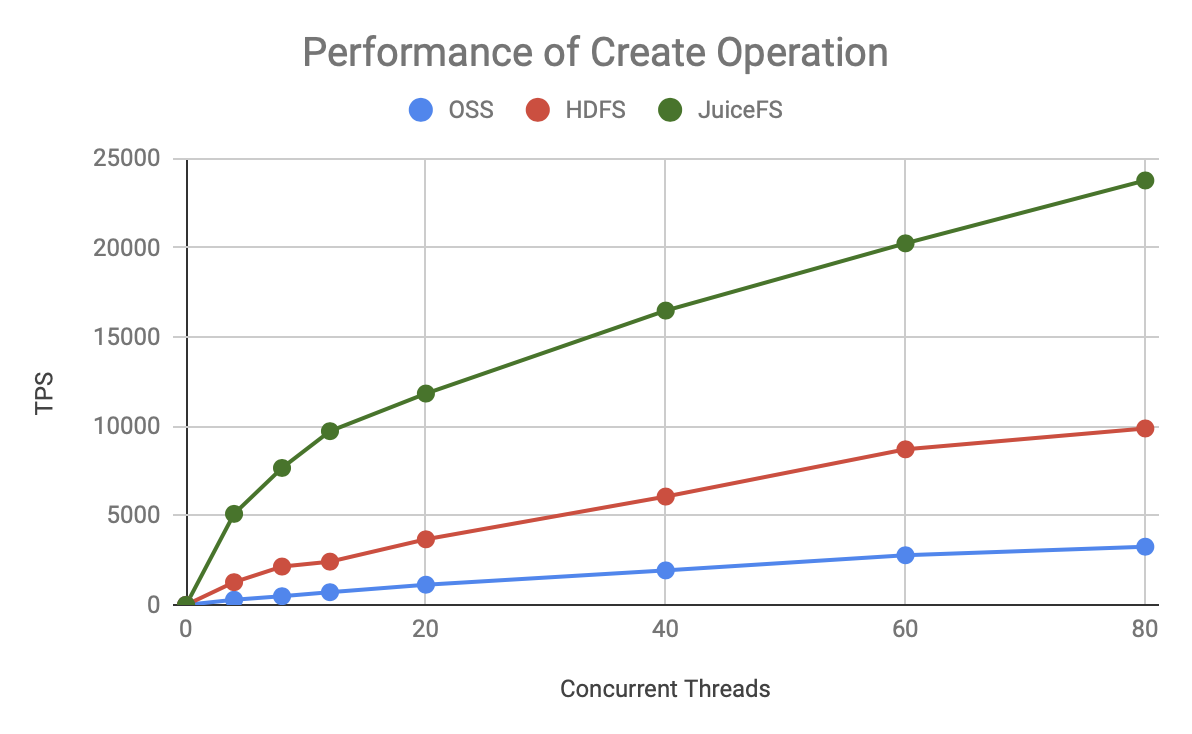
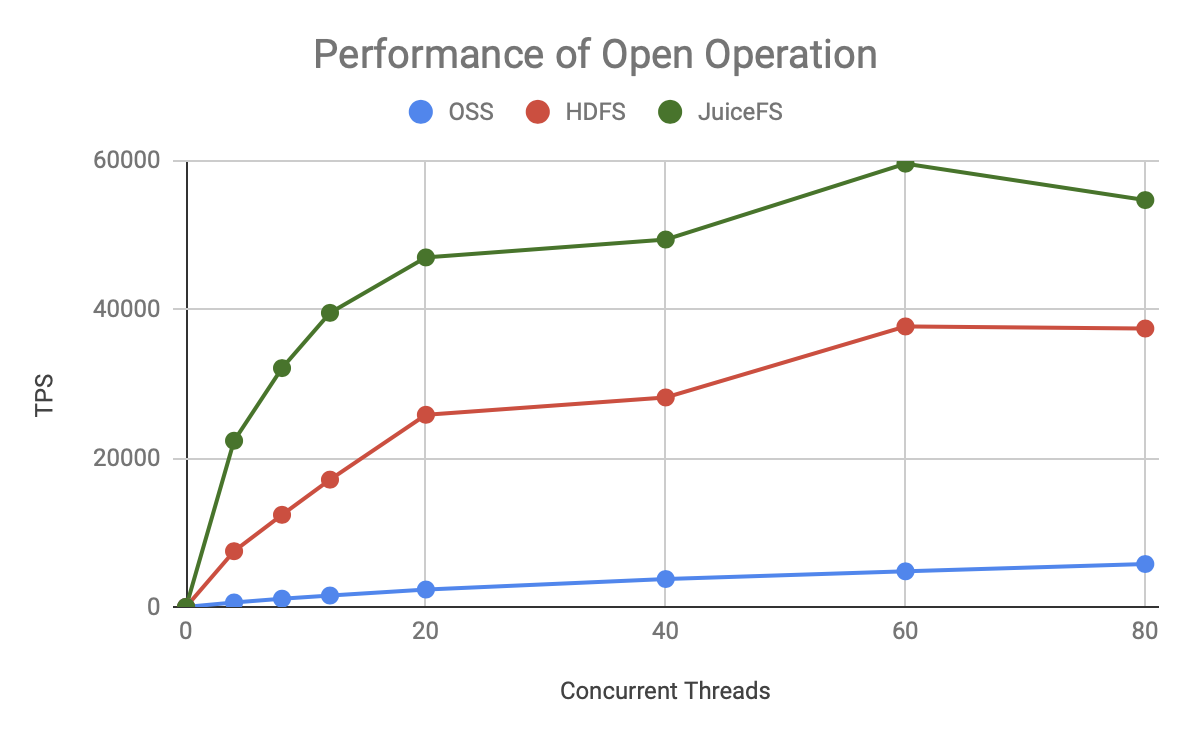
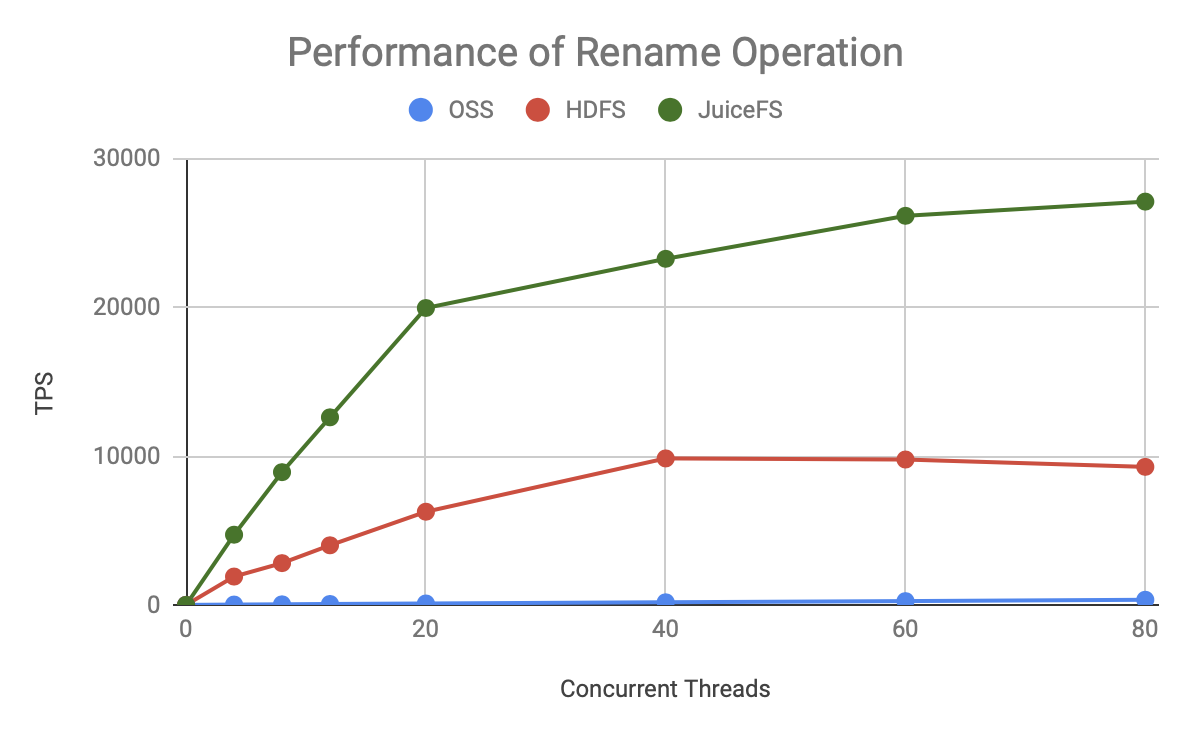
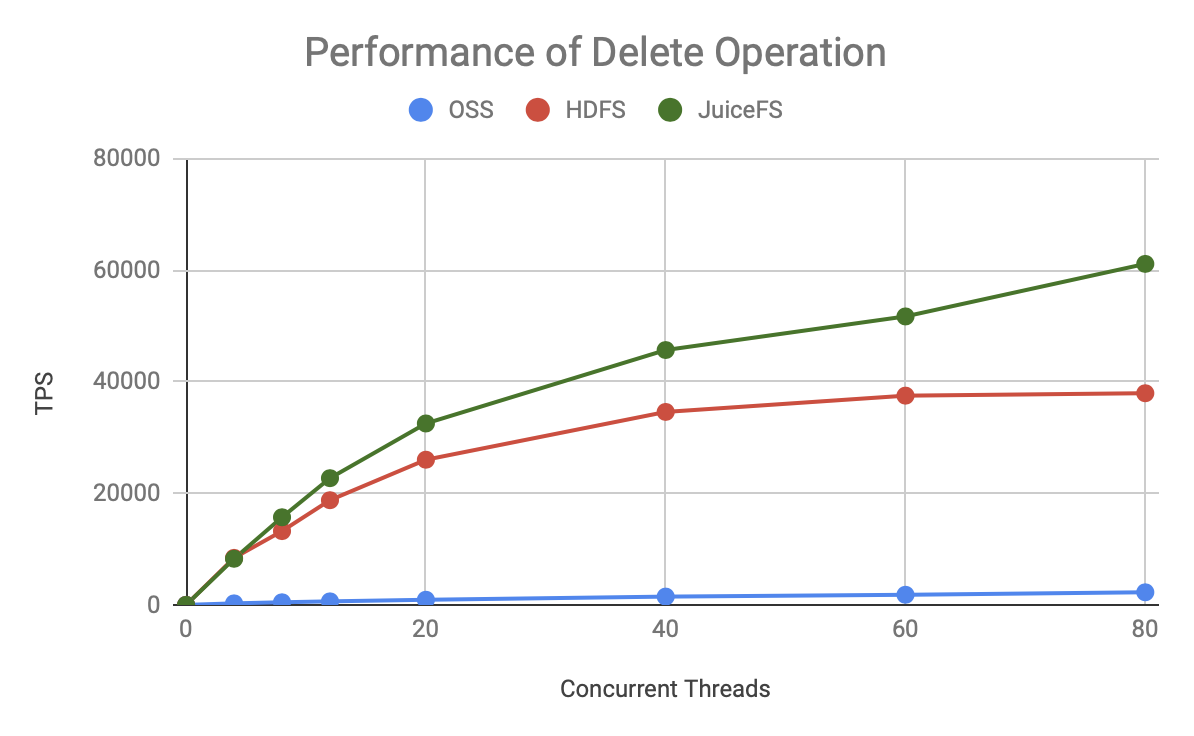
As you can see, for either metadata operation, JuiceFS has faster TPS growth and a higher ceiling, which is significantly better than HDFS and OSS.
Summary
Generally when we look at the performance of a system, we focus on its operation latency (time consumed by a single operation) and throughput (processing power under full load), and we put these two metrics back together as follows:
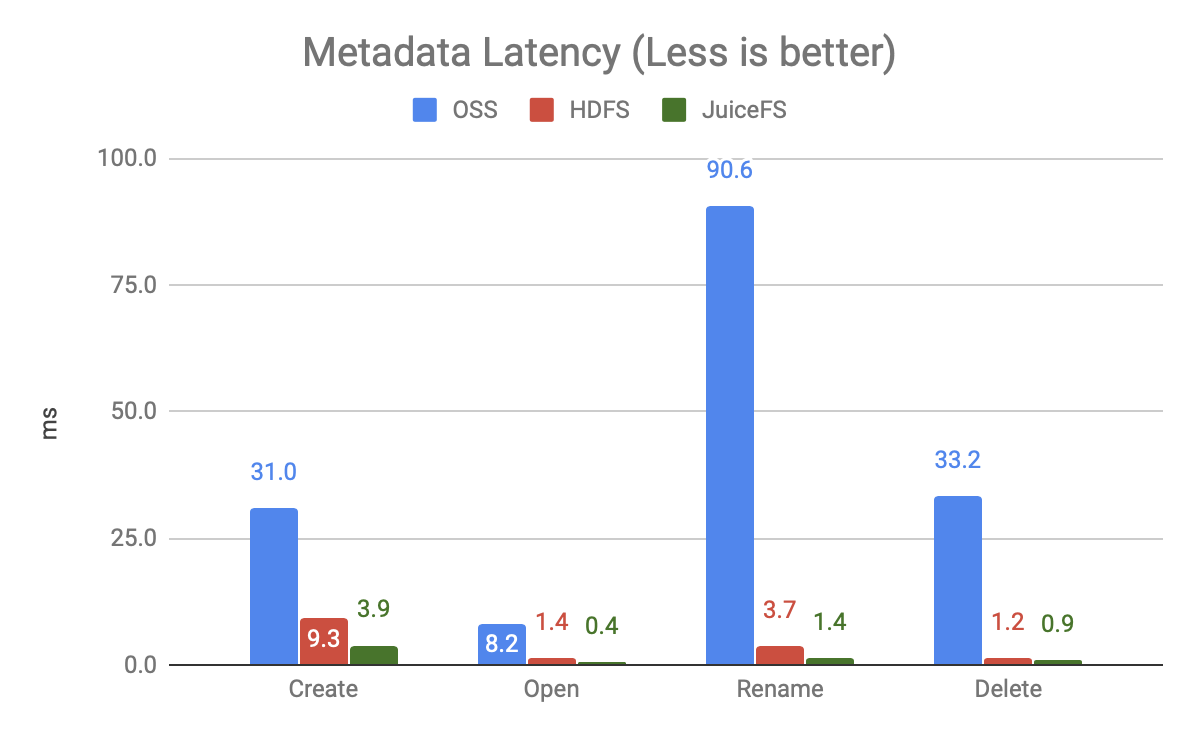
The graph above shows the latency of each operation under 20 concurrent operations (not running at full load) and shows that
- OSS is very slow, especially the Rename operation, because it is implemented by Copy + Delete. The test in this article is only the Rename of a single file, while the big data scenario is commonly used to Rename the whole directory, the gap will be even bigger.
- JuiceFS is faster than HDFS, more than twice as fast.
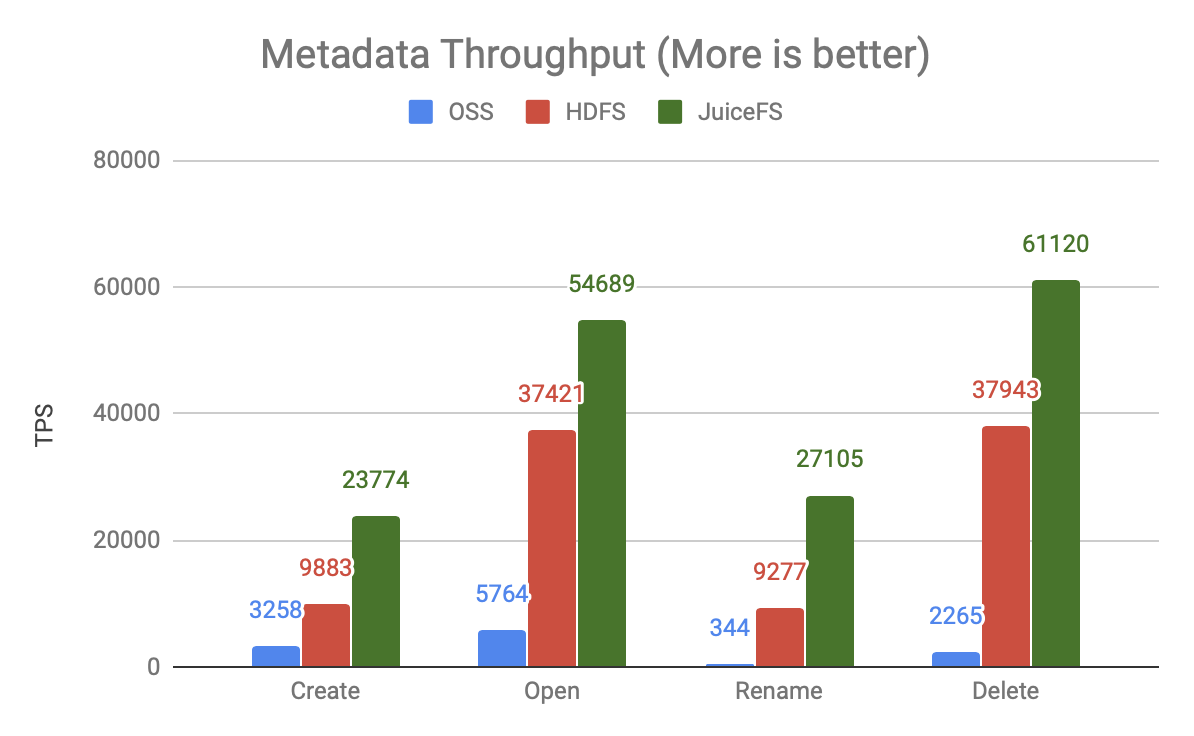
The above graph shows the throughput comparison with 80 concurrent users.
- The throughput of OSS is very low, one to two orders of magnitude different from the other two products, meaning it needs to use more compute resources and generate higher concurrency to get the same processing power.
- JuiceFS has 50-200% more processing power than HDFS, and the same resources can support larger scale computations.
From the above two core performance metrics, object storage is not suitable for performance-demanding big data analytics scenarios. JuiceFS as a latecomer has fully surpassed HDFS and is able to support larger scale compute processing with faster performance.



