







Background
Apache HBase is a large-scale, scalable, and distributed data storage service in the Apache Hadoop ecosystem. It is also a NoSQL database that was initially designed to provide random, consistent, real-time queries for billions of rows of records that contain millions of columns.
By default, HBase data are storing on HDFS, and HBase does many optimizations for HDFS to ensure stability and performance. However, maintaining HDFS itself is not easy. It requires constant monitoring, operation, and maintenance, tuning, expansion, disaster recovery, etc., and the cost of building HDFS on the public cloud is also quite expensive (compared at the end of the article).
To save money and reduce maintenance costs, some users use S3 (or other object storage) to store HBase data. The use of S3 eliminates the hassle of monitoring operation and maintenance, and also implements the separation of storage and calculation, making HBase's expansion and contraction easier. However, S3 is not a file system. Many HDFS API did not have corresponding implementations on S3. At the same time, some API of S3 does not have strong consistency guarantee, so the stability and performance of HBase are compromised.
Let's dig in what if we using JuiceFS as the data storage for HBase.
Introduction to JuiceFS
JuiceFS is a natural evolution of HDFS on the public cloud. First, it provides a high-performance, distributed metadata service that is fully compatible with the HDFS API. At the same time, it uses S3 and other object storages for data storage with the help of their flexibility, low cost, and fully-managed advantages.
Let's take a look at the JuiceFS architecture diagram:
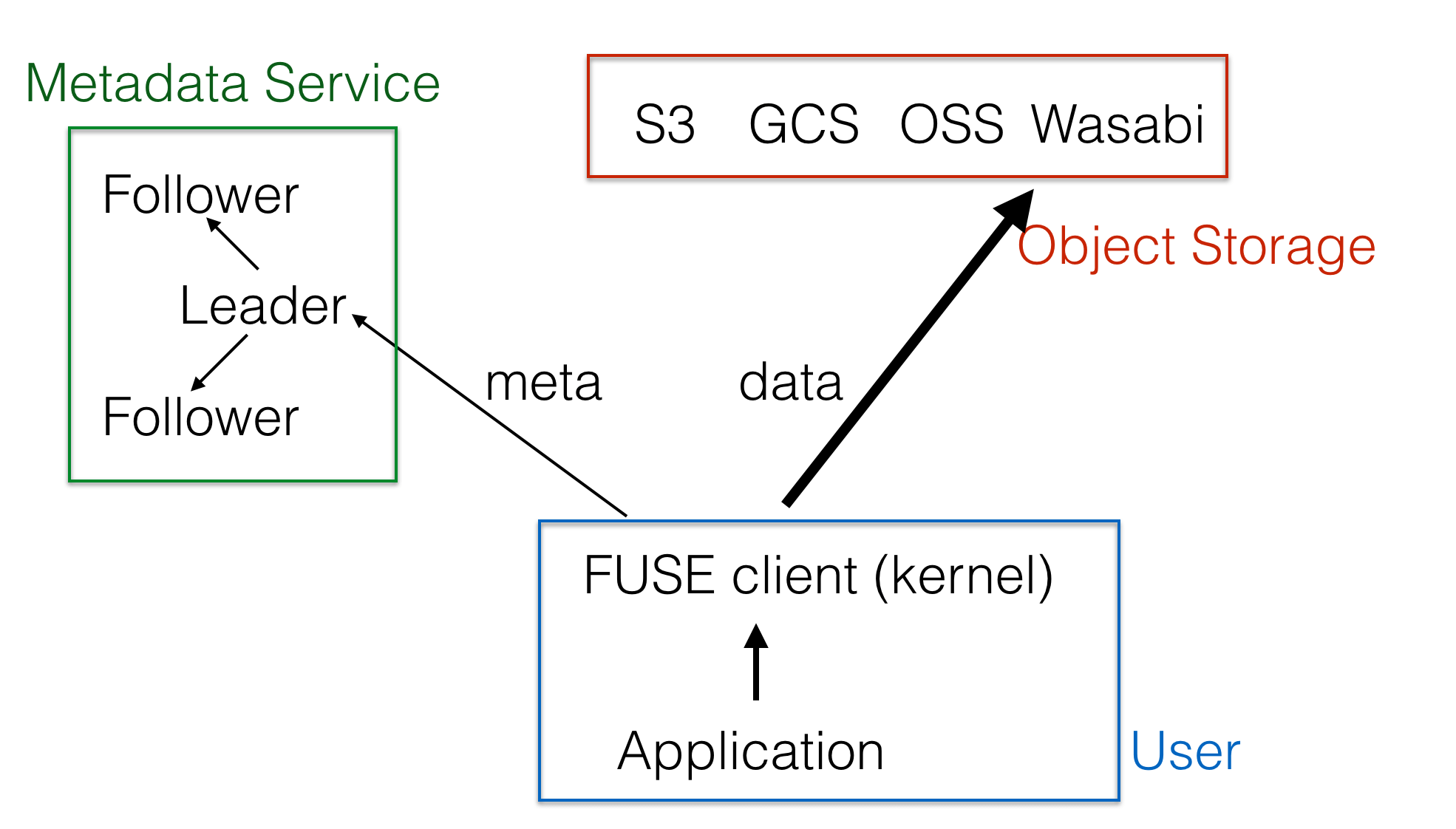
JuiceFS consists of two core parts:
- JuiceFS Metadata service;
- JuiceFS Java SDK, which is fully compatible with the HDFS API and also provides FUSE-based client mounts that are entirely POSIX compliant.
For details, please refer to official documentation.
Faster
Engineers are all concerned about performance. Let's do a benchmark.
We use the YCSB test set and plan to simulate the HBase cluster recovery scenario in the online production environment, so the test is performed after having run through and restarted HBase.
Test environment
- AWS EMR
- 2 core nodes (4Core 16G,500G EBS SSD)
- Region server (6G RAM)
Write comparison
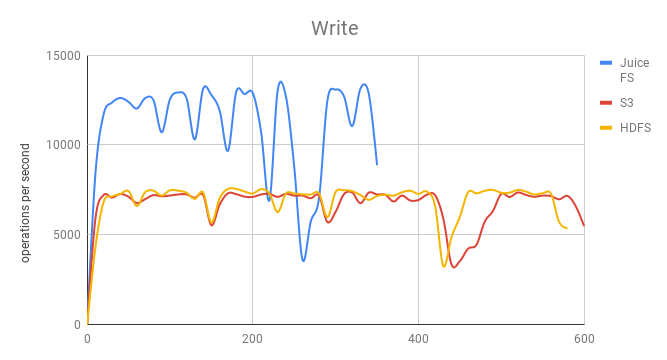
S3 and HDFS write performances are basically the same. JuiceFS has an increase of about 70%.
Since HBase uses an LSM tree, it has a log file and an in-memory storage structure to convert random write operations into sequential writes. Therefore, the main factor is the sequential write capability of the file system. JuiceFS uses concurrent multi-thread writes, and with the help of high-performance metadata capabilities, therefore remarkably faster than using S3 directly.
Single GET comparison
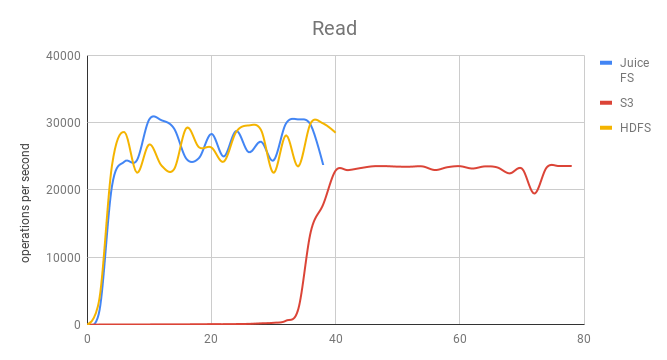
As you can see, the startup is very slow when using S3, mainly because there is no local disk cache, you need to rely on HBase Bucket Cache to cache data on the disk, to improve the cache hit rate, and this part of data will lose after the RegionSever restart, then all the data must be read from S3, which takes much time to reheat, it is obvious in the above figure.
When the data warm-up is completed, the performance is getting closer. At this time, the hot data is already cached in HBase's Block Cache.
JuiceFS supports data caching, which can fully cache hot data on a local disk. Therefore, when HBase restart, hot data can still be quickly warmed up through the cache in the local disk.
If you use SSD as a local cache disk, you can naturally achieve the effect of hot and cold data separation. Cold data will be automatically dropped from the cache when there is insufficient use, and the hot data will keep on the local cache disk.
From the test, JuiceFS and HDFS have almost the same performance. In other words, JuiceFS achieves the performance level of HDFS data locality in the case of storage computing separation.
More stable
When using S3 for storage, WAL cannot write to S3 directly due to performance issues, so users still need to maintain an additional HDFS cluster to store WAL data. Therefore, the workload of HDFS construction, monitoring, operation, and maintenance are not mitigated.
At the same time, because S3 is not a file system, this makes it difficult for HBase to run stably. Give two examples:
First, part of the S3 API has the eventual consistency guarantee. Therefore, when writing data in HBase and triggers flush, FileNotFoundException may raise, or newly written data may not be immediately visible, which will cause HBase unstable.
Another example, S3 does not provide an atomic rename operation, and HBase needs to rename in the drop table, so it can only be implemented in other ways. On the one hand, stability is affected, and on the other hand, the drop table consumes much time.
JuiceFS solves all the above problem. First of all, WAL can be written directly to JuiceFS, so there is no need to maintain HDFS. At the same time, JuiceFS guarantees strong data consistency and is fully compatible with the HDFS API. Therefore, the two problems mentioned above will not exist, and the stability and performance of the operation are at the same level of HDFS.
Cheaper
Next, let's talk about why it is costly to maintain HDFS on public clouds.
First of all, HDFS needs to build on the public cloud with cloud disk. Since the cloud disk has already made multiple copies, and the multiple copies required by HDFS will make the data transition redundant and increase the cost. However, if we disable HDFS to make multiple copies, DataNode will have a single point of failure availability issue.
Second, HDFS is coupled with computing resources. If the storage space is insufficient, HDFS expansion also needs to add a lot of CPU and memory, and the computing load of the cluster is probably low. You can't utilize these new resources and result in waste. If it is a storage and computing separation architecture that storage can elastically expand, this situation won't happen.
Third, talk about flexibility. HDFS needs to do expansion manually. Each time you want to expand, you need to increase the amount of space. The data will be gradually added. If the capacity of the expansion planned small, it is necessary to expand frequently, and the workload is massive. If the expansion planned large, the resource utilization rate would be low, increasing costs. Elastic storage services such as S3 and JuiceFS does not need to consider for expansion. Data can be written at will, pay as you go, and there is no waste.
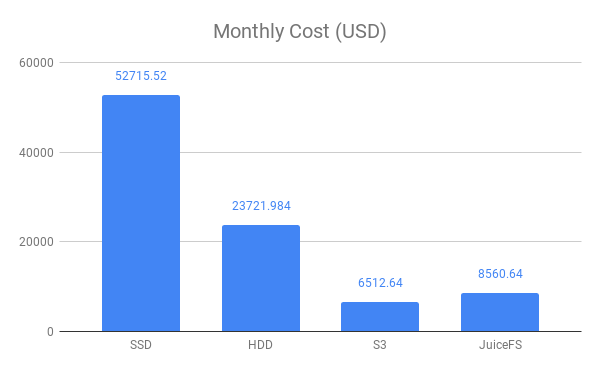
Let us calculate the account in detail below.
Per storage per GB price per month:
- Amazon EBS General Purpose SSD (gp2) Volume:0.132 USD
- Amazon EBS Throughput Optimized HDD (st1): 0.0594 USD
- S3 storage: 0.024 USD
- JuiceFS: 0.02 USD
Calculated according to the amount of 100T data:
- SSD and HDD for HDFS data disks, which need to have 3 copies, and need to consider 1.3 times the redundancy factor
- Both S3 and JuiceFS require 30% SSD space for local caching
Calculation method:
- The HDFS price is calculated as: per GB unit price * capacity * copies factor * redundancy factor
- The S3 price is calculated as: per GB unit price * capacity + hard disk cache per GB unit price * capacity * cache factor
- The JuiceFS price is calculated as: (S3 per GB unit price + JuiceFS per GB unit price) * capacity + hard disk cache per GB unit price * capacity * cache factor.
Monthly price comparison:
So, had the HDFS users thinking about cutting the expensive bills? Did the S3 users want to solve the stability issues?
For detailed deployment method please refer to JuiceFS for Hadoop Workloads (Replacing HDFS).



