













Enterprises are storing more data. The conflict between storage capacity and query performance as well as storage cost becomes a common challenge. This dilemma is particularly acute in the scenario of Elasticsearch and ClickHouse. In order to cope with the query performance requirements of different data, Elasticsearch and ClickHouse come with some architectural design strategies for data tiering.
Meanwhile, in terms of storage medium , with the development of cloud computing, object storage has gained favor with its low price and elastic scalable space. More and more enterprises are migrating warm and cold data to object storage. However, migrating the index and analysis components directly to object storage will hinder query performance and cause compatibility issues.
This article will elaborate the fundamentals of hot and cold data tiering in these two scenarios, and introduce how to use JuiceFS to cope with the problems that occur on object storage.
1 Elasticsearch’s data tier architecture
There are three concepts to be known before diving into how ES implements a hot and cold data tiering strategy: Data Stream, Index Lifecycle Management (ILM), and Node Role.
Data Stream
Data Stream is an important concept in ES, which has the following characteristics:
- Streaming writes. Data Stream is a data set written in stream rather than in block.
- Append-only writes. Data Stream updates data via append writes and does not require modifying existing data.
- Timestamp. A timestamp is given to each new piece of data to record when it was created.
- Multiple indexes: In ES, every piece of data resides in an Index. The data stream is a higher level concept, one data stream may compose of many indexes, which are generated according to different rules. However, only the latest index is writable, while the historical indexes are read-only.
Log data is a typical type of data steam. It is append-only and also has to be timestamped. The user will generate new indexes by different dimensions, such as day or others.
The scheme below is a simple example of index creation for a data stream. In the process of using the data stream, ES will write directly to the latest index. As more data is generated, this index will eventually become an old, read-only index.
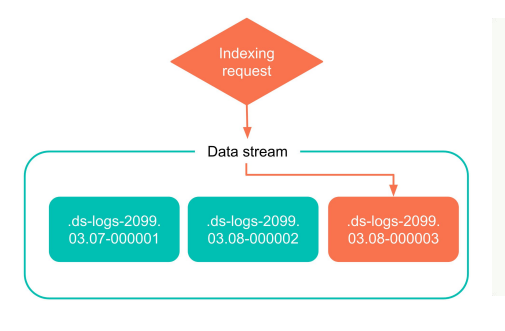
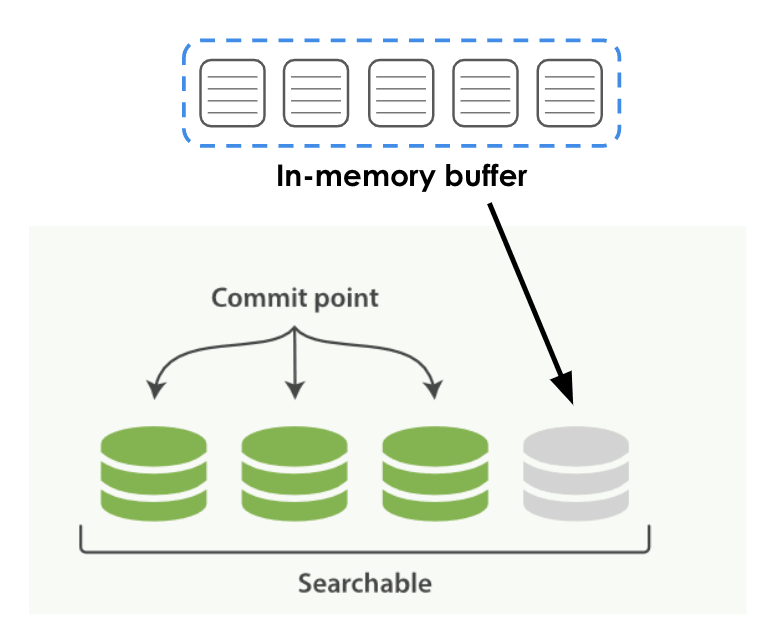
The following graph illustrates writing data to the ES, including two phases.
- Stage 1: the data is first written to the In-memory buffer.
- Stage 2: The buffer will fall to the local disk according to certain rules and time, which is shown as green in the graph (persistent data), known as segment in ES.
There may be some time lag in this process, and the newly created segment cannot be searched if a query is triggered during the persistence process. Once the segment is persisted, it can be searched by the upper-level query engine immediately.
Index Lifecycle Management
Index Lifecycle Management (ILM), is the lifecycle management of an index, and ILM defines the lifecycle of an index as 5 phases.
- Hot data: needs to be updated or queried frequently.
- Warm data: no longer updated, but is still frequently queried.
- Cold data: no longer updated and is queried less frequently.
- Frozen data: no longer updated and hardly ever queried. It is safe to put this kind of data in a relatively low-speed and cheap storage medium.
- Deleted data: no longer needed and can be safely deleted.
All ES index data will eventually go through these stages, users can manage their data by setting different ILM policies.
Node Role
In ES, each deployment node will have a Node Role. Different roles, such as master, data, ingest, etc., will be assigned to each ES node. Users can combine the Node Roles, and the different lifecycle phases mentioned above, for data management.
The data node has different stages, and it can be a node that stores hot data, warm data, cold data, or even extremely cold data. The node will be assigned different roles based on its tasks, and different nodes are sometimes configured with different hardware depending on roles.
For example, hot data nodes need to be configured with high-performance CPUs or disks, for nodes with warm and cold data, as these data are queried less frequently, the requirement for hardware is not necessarily high for some computing resources.
Node roles are defined based on different stages of the data lifecycle. It is important to note that each ES node can have multiple roles, and these roles do not need to have a one-to-one relationship. Here's an example where node.roles is configured in the ES YAML file. You can also configure multiple roles for the node that it should have.
node.roles: ["data_hot", "data_content"]
Lifecycle Policy
After understanding the concepts of Data Stream, Index Lifecycle Management, and Node Role, you can customize lifecycle policies for your data.
Based on the different dimensions of index characteristics defined in the policy, such as the size of the index, the number of documents in the index, and the time when the index was created, ES can automatically help users roll over data from one lifecycle stage to another, which is known as rollover in ES.
For example, the user can define features based on the size of the index and roll over the hot data to the warm data, or roll over the warm data to the cold data according to some other rules. ES can do the job automatically, while the lifecycle policy needs to be defined by the user.
The screenshot below shows Kibana's administration interface, which allows users to graphically configure lifecycle policies. You can see that there are three phases:hot data, warm data, and cold data.
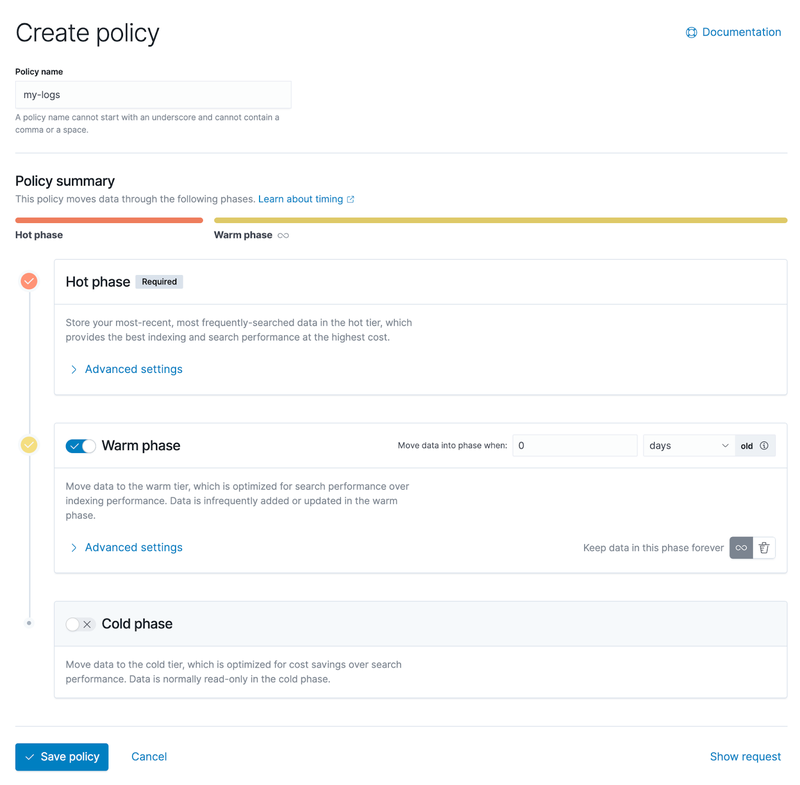
Expanding the advanced settings, you can see more details about configuration policies based on different characteristics,which is listed on the right side of the screenshot below.
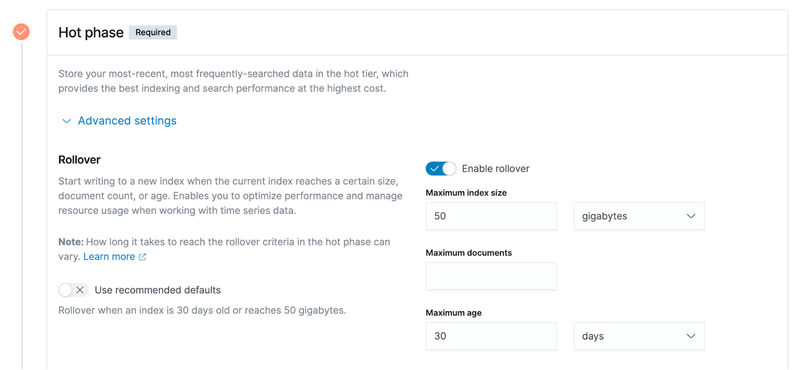
- Maximum index size. Take an example of 50 GB in the above screenshot. It means that data will be rolled from the hot data phase to the warm data phase when the size of the index exceeds 50GB.
- Maximum documents. The basic storage unit of ES index is document, and the user data is written to ES in the form of documents. Thus, the number of documents is a measurable indicator.
- Maximum age. As an example of 30 days, i.e., an index has been created for 30 days, it will trigger the rollover of the hot data to the warm data phase as mentioned previously.
2 ClickHouse’s data tier architecture
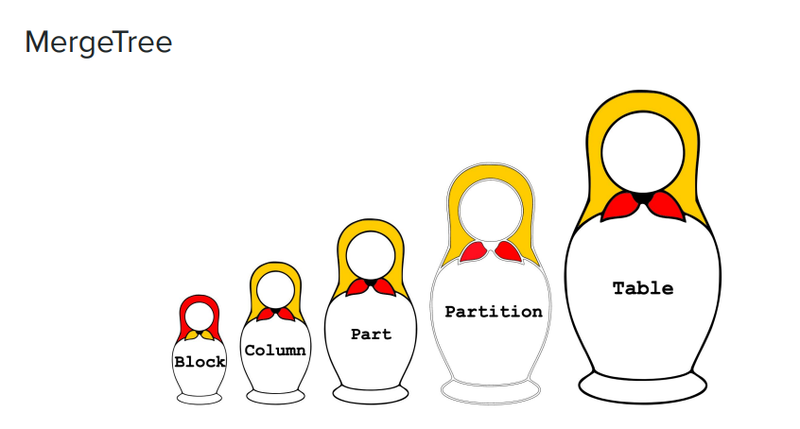
The image below shows a set of Russian nesting dolls from large to small, which well illustrates ClickHouse's data management model via the MergeTree engine. The MergeTree engine composes of the following elements:
- Table. It is the largest concept shown on the most right of the image, which is the first thing that the user needs to create or access in ClickHouse.
- Partition. It is a smaller dimension with a smaller granularity compared to ”table“. In ClickHouse, the data is divided into partitions to store, and each partition has an identity.
- Part. Each partition can be further divided into smaller parts. If you’ve checked the format of the data stored on ClickHouse disks, each subdirectory can be considered as a part.
- Column. Part contains data with even smaller granularity, i.e. column. Data is stored by column in ClickHouse. There are many columns in the part directory, for example, there will be 100 Column files for a table with 100 columns.
- Block. Each Column file is organized by the granularity of block.
As the following example, there are four subdirectores under the table directory, and each subdirectory refers to a part.
$ ls -l /var/lib/clickhouse/data/<database>/<table>
drwxr-xr-x 2 test test 64B Aug 8 13:46 202208_1_3_0
drwxr-xr-x 2 test test 64B Aug 8 13:46 202208_4_6_1
drwxr-xr-x 2 test test 64B Sep 8 13:46 202209_1_1_0
drwxr-xr-x 2 test test 64B Sep 8 13:46 202209_4_4_0In the rightmost column of the above example, the name of each subdirectory is preceded by time, i.e., 202208, but 202208 is also the partition name, which can be defined by user but usually named by time.
For example, the partition, 202208, will have two subdirectories (i.e., parts), and each partition usually consists of multiple parts. When writing data to ClickHouse, data will be written to memory first, and then persisted to disk according to the data structure in memory. If the data in a partition is too large, the partition will become many parts on the disk. ClickHouse doesn’t recommend creating too many parts under one table, it will also merge parts to reduce its total number. This is one of the reasons why it’s called the MergeTree engine.
There is another example helping us to understand “part” in ClickHouse. There are many small files in the part, some of which are meta-information, such as index information, which facilitates lookup performance.
$ ls -l /var/lib/clickhouse/data/<database>/<table>/202208_1_3_0
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnA.bin
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnA.mrk
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnB.bin
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnB.mrk
-rw-r--r-- 1 test test ?? Aug 8 14:06 checksums.txt
-rw-r--r-- 1 test test ?? Aug 8 14:06 columns.txt
-rw-r--r-- 1 test test ?? Aug 8 14:06 count.txt
-rw-r--r-- 1 test test ?? Aug 8 14:06 minmax_ColumnC.idx
-rw-r--r-- 1 test test ?? Aug 8 14:06 partition.dat
-rw-r--r-- 1 test test ?? Aug 8 14:06 primary.idxThe most right column of the above example, the files prefixed by Column are actual data files, which are relatively large compared to meta information. There are only two columns in this example, A and B, and a table may consist of many columns in actual uses. All these files, including meta and index information, will together help users to quickly jump between files or look up files.
ClickHouse storage policy
If you want to tier hot and cold data in ClickHouse, you will use a lifecycle policy similar to the one mentioned in ES, which is called Storage Policy in ClickHouse.
Slightly different from ES, ClickHouse does not divide data into different stages, i.e., hot, warm, cold. Instead, ClickHouse provides some rules and configuration methods that require users to develop their own data tiering policy.
Each ClickHouse node supports the simultaneous configuration of multiple disks, and the storage medium can be varied. For example, users usually configure a ClickHouse node with an SSD for better performance; for warm and cold data, users can store the data in a medium with a lower cost, such as a mechanical disk. Users of ClickHouse will not be aware of the underlying storage medium.
Similar to ES, ClickHouse users need to create a storage policy based on data characteristics, such as the size of each subdirectory in part, the proportion of space left on the entire disk, etc. The execution of the storage policy is triggered when a certain data characteristic occurs. This policy will migrate one part from one disk to another. In ClickHouse, multiple disks configured in the same node have priority, and by default data will fall on the highest priority disk. This enables the transfer of the part from one storage medium to another.
Data migration can be triggered manually through SQL commands in ClickHouse, such as MOVE PARTITION/PART, and users can also do function validation through these commands. Secondly there may be some cases where explicitly need to move a part from the current storage medium to another one by manual means.
ClickHouse also supports time-based migration policy, which is independent of the storage policy. After data is written, ClickHouse triggers the migration of data on disk according to the time set by the TTL property of each table. For example, if the TTL is set to 7 days, ClickHouse will re-write the data in the table, which is older than 7 days, from the current disk (e.g. default SSD) to another lower priority disk (e.g. JuiceFS)
3 Storage of warm and cold data: object storage + JuiceFS
When migrating warm and cold data to the cloud, storage costs drop significantly compared to traditional SSD architectures. What’s more, Enterprises embrace the elastic scaling storage on the cloud without the need of O&M operations, such as scaling up or down and housekeeping. Warm and cold data requires a lot more storage capacity than hot data, especially over time. If all this data is stored locally, the corresponding O&M work will be overwhelming.
However, the use of data application components like Elasticsearch and ClickHouse directly on object storage can cause poor write performance and compatibility and other issues. Thus, companies that also want to balance query performance are starting to look for solutions on the cloud. Under this context, JuiceFS is increasingly being used in data tiering architectures.
The following test results of the ClickHouse write performance clearly present the difference between SSD, JuiceFS and object storage.
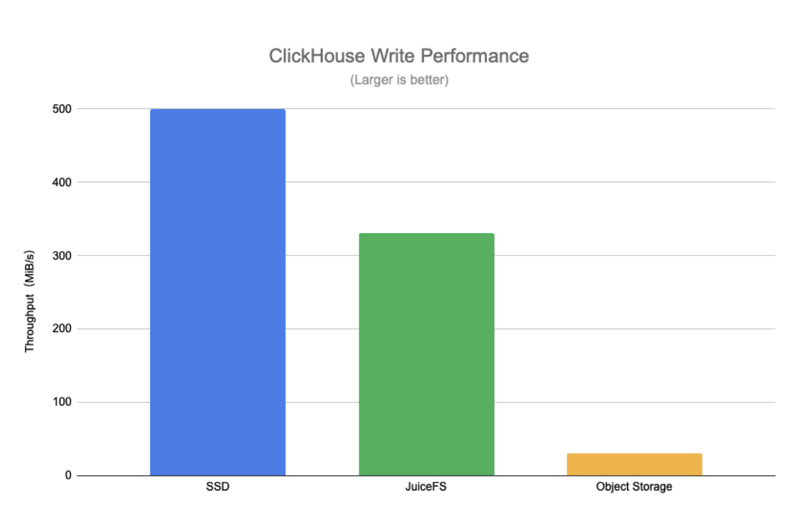
JuiceFS write throughput is much higher than direct writing on object storage, the throughput is close to that of SSD. There are certain requirements for write performance when users migrate hot data to the warm data tier. In the migration process, if the write performance of the underlying storage medium is poor, the whole migration process will be slowed down and last for a long time, which will also bring some challenges for the whole pipeline or data management.
The figure below compares the query performance of SSD, JuiceFS and object storage using the data in different actual scenarios. Where q1-q4 are queries that scan the full table and q5-q7 are queries that hit the primary key index.
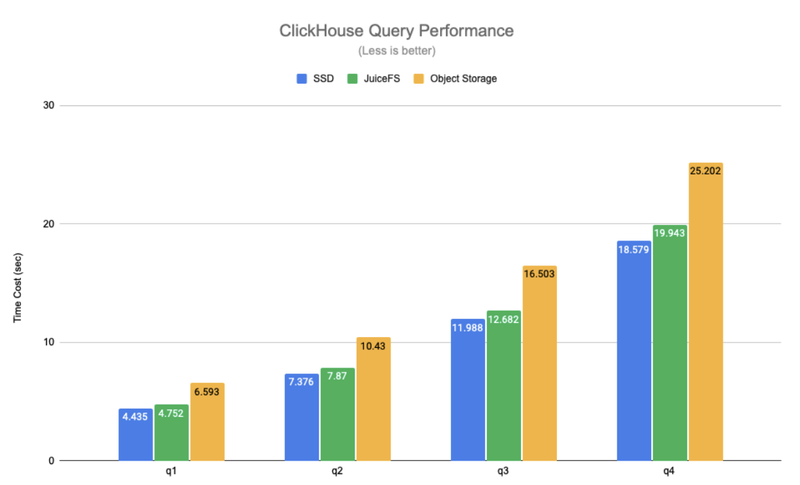
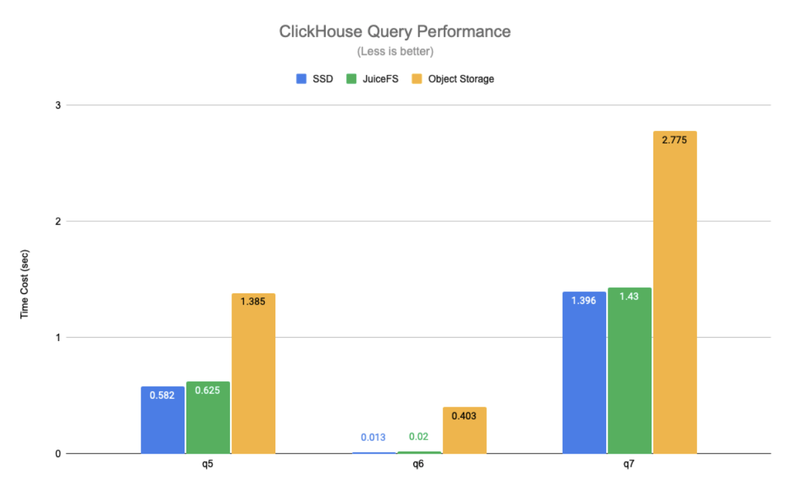
The test results show that JuiceFS and SSD have a comparable query performance, with an average difference of about 6%, but object storage has a 1.4 to 30x performance degradation compared to SSD. Thanks to JuiceFS' high-performance metadata operations and local caching features, the hot data needed for query requests is automatically cached locally on ClickHouse nodes, which significantly improves ClickHouse's query performance. It should be noted that the object storage in the above tests is accessed through ClickHouse's S3 disk type, and, in this way, only data is stored on the object store, while metadata is still stored on the local disk. If the object store is mounted locally in a similar way to S3FS, performance will be further degraded.
It is also worth mentioning that JuiceFS is a fully POSIX-compatible file system, which works well with applications like Elasticsearch andClickHouse, and users are not aware of whether the underlying storage is a distributed file system or a local disk. In comparison, the direct use of object storage cannot achieve good compatibility with applications.
4 practice of ES + JuiceFS
Step 1: Prepare multiple types of nodes and assign different roles. Each ES node can be assigned different roles, such as storing hot data, warm data, cold data, etc. Users need to prepare different types of nodes to match the needs of different roles.
Step 2: Mount the JuiceFS file system. Generally users use JuiceFS for warm and cold data storage, users need to mount the JuiceFS file system locally on the ES warm data node or cold data node. The user can configure the mount point into ES through symbolic links or other means to make ES think that its data is stored in a local directory, but this directory is actually a JuiceFS file system.
Step 3: Create a lifecycle policy. This needs to be customized by each user, either through the ES API or through Kibana, which provides some relatively easy ways to create and manage lifecycle policies.
Step 4: Set a lifecycle policy for the index. After creating a lifecycle policy, you need to apply the policy to the index, that is, you need to set the policy you just created for the index. You can do this by using index templates, which can be created in Kibana, or explicitly configured through the API via index.lifycycle.name.
Here are a few tips.
Tip 1: The number of copies (replicas) of Warm or Cold nodes can be set to 1. All data is placed on JuiceFS, eventually uploaded to the underlying object storage, so the reliability of the data is high enough. Accordingly, the number of copies can be reduced on the ES side to save storage space.
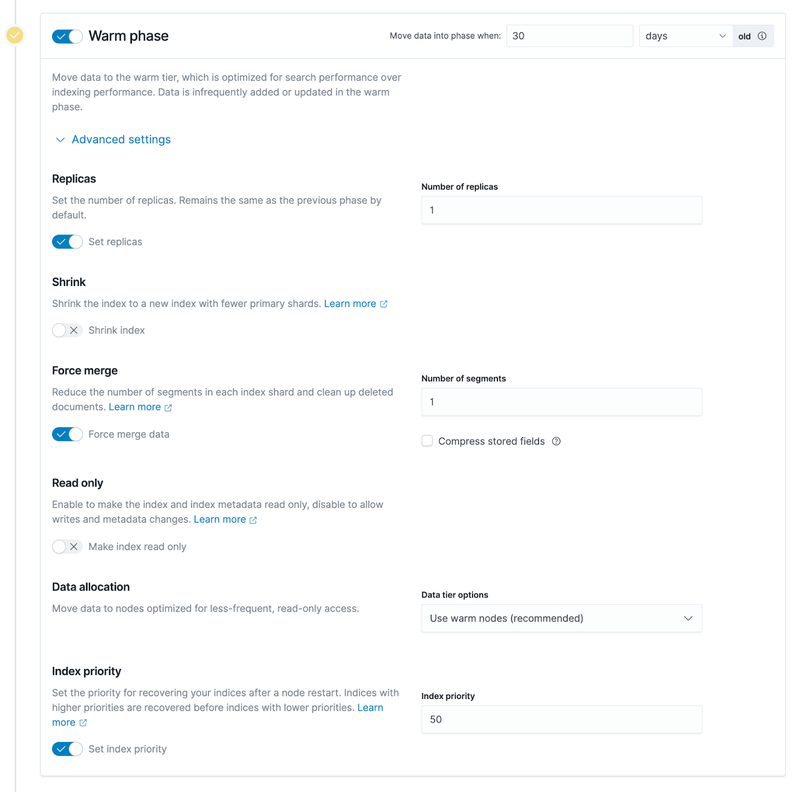
Tip 2: Turning on Force merge may cause constant CPU usage on nodes, so turn it off if appropriate. When moving from hot data to warm data, ES will merge all the underlying segments corresponding to the hot data index. If Force merge is enabled, ES will first merge these segments and then store them in the underlying system of warm data. However, merging segments is a very CPU-consuming process. If the data node of warm data also needs to carry some query requests, you can turn off this function as appropriate, that is, keep the data intact and write it to the underlying storage directly.
Tip 3: The index of Warm or Cold phase can be set to read-only. When indexing warm and cold data phases, we can basically assume that the data is read-only and the indexes will not be modified. Setting the index to read-only can reduce some resource usage on the warm and cold data nodes, you can then scale down these nodes and save some hardware resources.
5 Practice on ClickHouse + JuiceFS
Step 1: Mount the JuiceFS file system on all ClickHouse nodes. Any path would work because ClickHouse will have a configuration file to point to the mount point.
Step 2: Modify the ClickHouse configuration to add a new JuiceFS disk. Add the JuiceFS file system mount point that you just mounted in ClickHouse so that ClickHouse can recognize this new disk.
Step 3: Add a new storage policy and set the rules for sinking data. This storage policy will automatically sink data from the default disk to the specified store, such as JuiceFS, according to the user's rules.
Step 4: Set the storage policy and TTL for a specific table. After the storage policy is set, you need to apply the policy to a table. In the pre-testing and validation phases, it is recommended to use a relatively large table, and if users want to achieve data sinking based on the time dimension, they need to set the TTL on the table at the same time. The whole sinking process is automatic, you can check the parts that are currently processing data migration and migration progress through ClickHouse's system table.
Step 5: Manually move the part for validation. You can verify whether the current configuration or storage policy is in effect by manually executing the MOVE PARTITION command.
As an example below, ClickHouse has a configuration item called `storage_configuration`, which contains disks configuration, in which JuiceFS is added as a disk and named "jfs" (the name is arbitrary) and the mount point is the /jfs directory.
<storage_configuration>
<disks>
<jfs>
<path>/jfs</path>
</jfs>
</disks>
<policies>
<hot_and_cold>
<volumes>
<hot>
<disk>default</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</hot>
<cold>
<disk>jfs</disk>
</cold>
</volumes>
<move_factor>0.1</move_factor>
</hot_and_cold>
</policies>
</storage_configuration>Further down are the policies configuration items, where a storage policy called `hot_and_cold` is defined, and the user needs to define some specific rules, such as prioritizing the volumes in order of hot first and then cold, with the data first falling to the first hot disk in the volumes and the default ClickHouse disk (usually the local SSD).
The `max_data_part_size_bytes` configuration in volumes means that when the size of a part exceeds the set size, the storage policy will be triggered and the corresponding part will sink to the next volume, i.e. cold volume. In the above example, JuiceFS is the cold volume.
The bottom `move_ factor` configuration means that ClickHouse will trigger the execution of the storage policy based on the portion of the remaining disk space.
CREATE TABLE test (
d DateTime,
...
) ENGINE = MergeTree
...
TTL d + INTERVAL 1 DAY TO DISK 'jfs'
SETTINGS storage_policy = 'hot_and_cold';As the above code snippet shows, you can set the storage_policy to the previously defined hot_and_cold storage policy in SETTINGS when you create a table or modify the schema of this table. The TTL in the second to last line of the above code is the time-based tiering rule mentioned above. In this example, we specify a column called d in the table, which is of type DateTime; with INTERVAL 1 DAY, that line of code presents that the data will be transferred to JuiceFS when new data is written in for more than one day.
6 Outlook
- Copy sharing. Both ES and ClickHouse have multiple copies to ensure data availability and reliability. JuiceFS is essentially a shared file system, and once any copy of data is written to JuiceFS, there is no longer a need to maintain multiple copies. For example, if a user has two ClickHouse nodes, both with copies of a table or a part and sunk to JuiceFS, the same data may be written twice. We are still exploring whether we can make high level engine such as ES/ClickHouse to take into account of shared storage and reduce the number of copies when the data is sunk. Thus copies can be shared among different nodes. From the application layer, the number of parts is still multiple copies when a user is looking at the table, but in reality only one copy is kept on the underlying storage since essentially the data can be shared.
- Failure recovery. When the data has been sunk to a remote shared storage, if the ES or ClickHousle node goes down, how can we quickly recover from the failure? Most of the data other than hot data has actually been moved to remote shared storage, so if you want to recover or create a new node at this time, the cost will be much lighter than the traditional local disk-based failure recovery, which is worth further exploring in ES or ClickHouse scenarios.
- Separation of storage and computing. The whole community has been exploring how to turn traditional local disk-based storage system into real storage and computing separation system in the cloud-native environment. However, storage and compute separation is not just a simple separation of data and compute, but to meet the various complex requirements of the upper layer, such as the demands for query performance, write performance, and various dimensional tuning. Thus, there are still many technical difficulties worth exploring in the field of storage separation.
- Exploration of data tiering for other upper-layer application components. In addition to ES and ClickHouse scenarios, we have also made some attempts to sink warm and cold data from Apache Pulsar into JuiceFS recently, using some strategies and schemes similar to those mentioned in this article. The only difference is that in Apache Pulsar, the data types or data formats that need to sink are different from ES and ClickHouse. We will share further successful practices once available.



