Xiaomi is one of the world's leading smartphone companies. It has also established the world’s leading consumer AI+IoT platform, with 654.5 million smart devices connected to its platform as of June 30, 2023. Xiaomi products are present in 100+ countries and regions around the world. We’ve extensively incorporated AI technology into hundreds of products, including smartphones, televisions, smart speakers, and translation devices. These AI applications are primarily developed through our deep learning training platform.
For the training platform storage, we tried various methods, including Ceph+NFS, HDFS, and object storage mounting. However, these various storage approaches caused increased data redundancy and maintenance costs and posed challenges of scalability and performance. Furthermore, as we advanced our cloud-native transformation, more applications were migrating from bare metal servers to container platforms. This emphasized our need for file storage and multi-node shared data access.
Therefore, we’ve built a file storage platform using JuiceFS, an open-source distributed file storage system. It provides cloud-native storage capabilities through the CSI Driver component to address file storage requirements in various application scenarios.
Currently, this platform hosts 5 billion+ files with a total capacity exceeding 2.5 PB, achieving cluster throughput of 300~400 Gbps. Our application scenarios are expanding, covering areas such as large model data storage, big data, and data lake migration to the cloud.
In this article, we’ll deep dive into why we needed a unified storage platform, why we chose JuiceFS, and how we use it at Xiaomi.
Why we needed a unified storage platform
Previously, we faced the following increasing demands:
- Growing application scenarios: As our AI applications grew, our need for large-scale file storage was skyrocketing. Scenarios like data sharing within containers, the separation of storage and computation, cloud migration of big data, and accommodating large models all required efficient and reliable file storage services.
- A unified file storage solution: Before we used JuiceFS, we employed various data storage methods like Ceph RBD + NFS, S3 FUSE, and HDFS on our machine learning platform. Our aim was to unify our storage approach, consolidating most of our data onto a single storage platform to reduce maintenance and data redundancy costs.
- Hybrid cloud environments: Xiaomi operates globally with business operations in multiple countries. We needed to cater to file storage requirements in both private and public cloud environments.
We envisioned our storage platform to exhibit the following characteristics:
- Feature-rich, with comprehensive storage capabilities supporting multiple access protocols like POSIX, designed for cloud-native platforms.
- Scalability to handle tens of billions of files and hundreds of petabytes of data, with elastic scaling capabilities.
- Striking the right balance between performance and cost to meet high-concurrency AI training demands while ensuring service stability and cost-effectiveness.
- Compatibility with various storage backends and support for diverse application environments, both on-premises and in the cloud.
- A development approach emphasizing iteration, aiming to leverage open-source projects and avoid reinventing the wheel, ensuring ease of development, scalability, and maintenance.
Storage selection: CephFS vs. JuiceFS
We conducted a performance and feature comparison between JuiceFS, CephFS, and other file storage systems.
CephFS’ drawbacks
CephFS had limitations in meeting our requirements. For example:
-
We desired deployment in the public cloud, while CephFS might be better suited for use in IDC environments.
-
At a certain cluster scale, for example, at the petabyte level, CephFS might encounter some bottlenecks in balancing and metadata server performance.
Why we chose JuiceFS
We selected JuiceFS as the foundation for our overall storage service based on the following factors:
- Compared to other open-source file storage systems like CephFS, JuiceFS adopts a plugin-based design, providing us with greater flexibility for customization based on our specific needs.
- JuiceFS also offers rich product features to meet our particular scenario requirements.
- Considering that Ceph had been widely used as a backend storage service within Xiaomi for many years, we could use Ceph RADOS as the data storage pool for JuiceFS. This would provide high-performance and low-latency file storage services within our data centers.
JuiceFS’ advantages
The following figure shows the JuiceFS architecture:
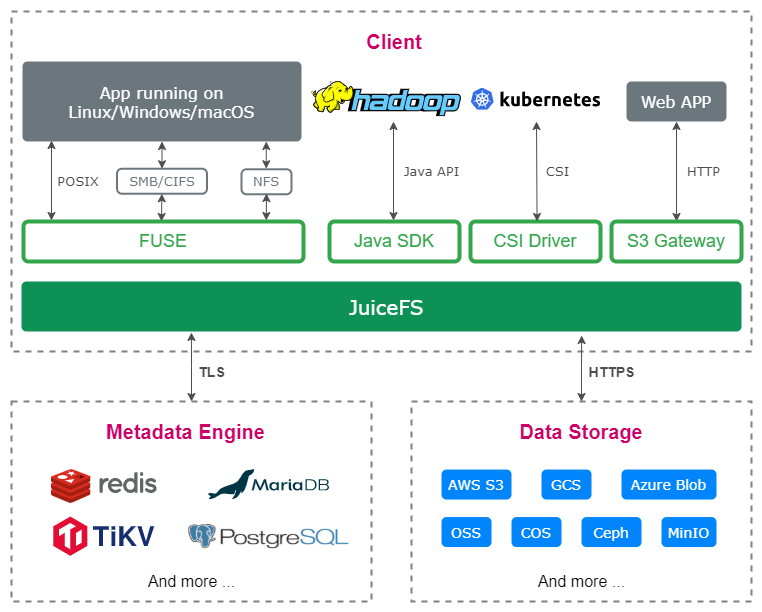
We decided to build a high-performance, cloud-native, and highly scalable shared file system based on JuiceFS, because it has the following advantages:
- JuiceFS employs a data and metadata separation storage architecture, with a fully pluggable design, which we find highly impressive. During our development based on JuiceFS, we could effortlessly adapt to internal enterprise needs and fully utilize existing mature components to meet data management requirements across different application scenarios.
- JuiceFS offers a wide array of features, supporting multiple access protocols, including POSIX, HDFS, and S3. It includes features such as data encryption, compression, and file locking and provides support for the CSI component. Additionally, it offers advanced extension capabilities, meeting our basic storage needs.
- JuiceFS has high performance. It delivers exceptional throughput performance to clients due to its unique data slice management and client-side caching acceleration capabilities.
- The JuiceFS community ecosystem is highly vibrant. Based on my interaction with various projects, I firmly believe that the JuiceFS community operates exceptionally well. It's worth noting that JuiceFS accumulated valuable experience in the commercial domain before open-sourcing, which has provided us with invaluable insights.
Our storage platform architecture and capabilities
As a file storage platform, our service is at the foundational level, designed to meet a diverse range of needs within Xiaomi. These scenarios encompass not only basic applications like self-driving but also include container-shared storage, big data, and various other use cases. Our goal is to provide productized features to application units, enhance service usability, and make it easier for application teams to use our services.
The following figure shows our storage platform architecture:
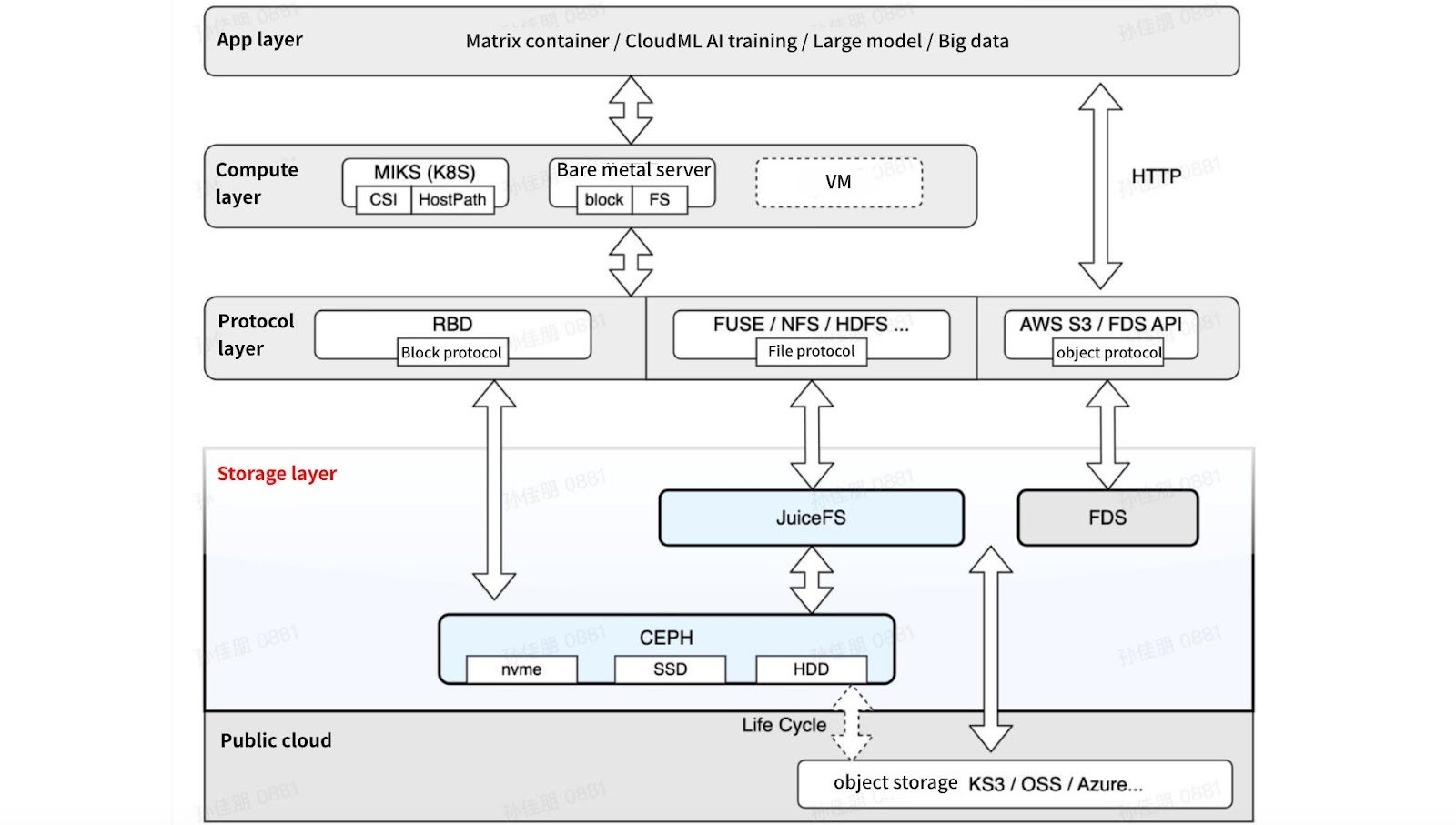
As a storage platform, we offer not only JuiceFS file storage services but also block storage services based on Ceph RBD. Additionally, Ceph provides the underlying object storage support for JuiceFS. We also have an internal FDS object storage service that can adapt to IDCs and various public cloud object storage solutions, offering seamless multi-cloud service support to our applications. We provide different protocol support to the upper layers, including block, file, and object protocols. At a higher level, we support PaaS platforms and the computing layer. The top layer is the application layer.
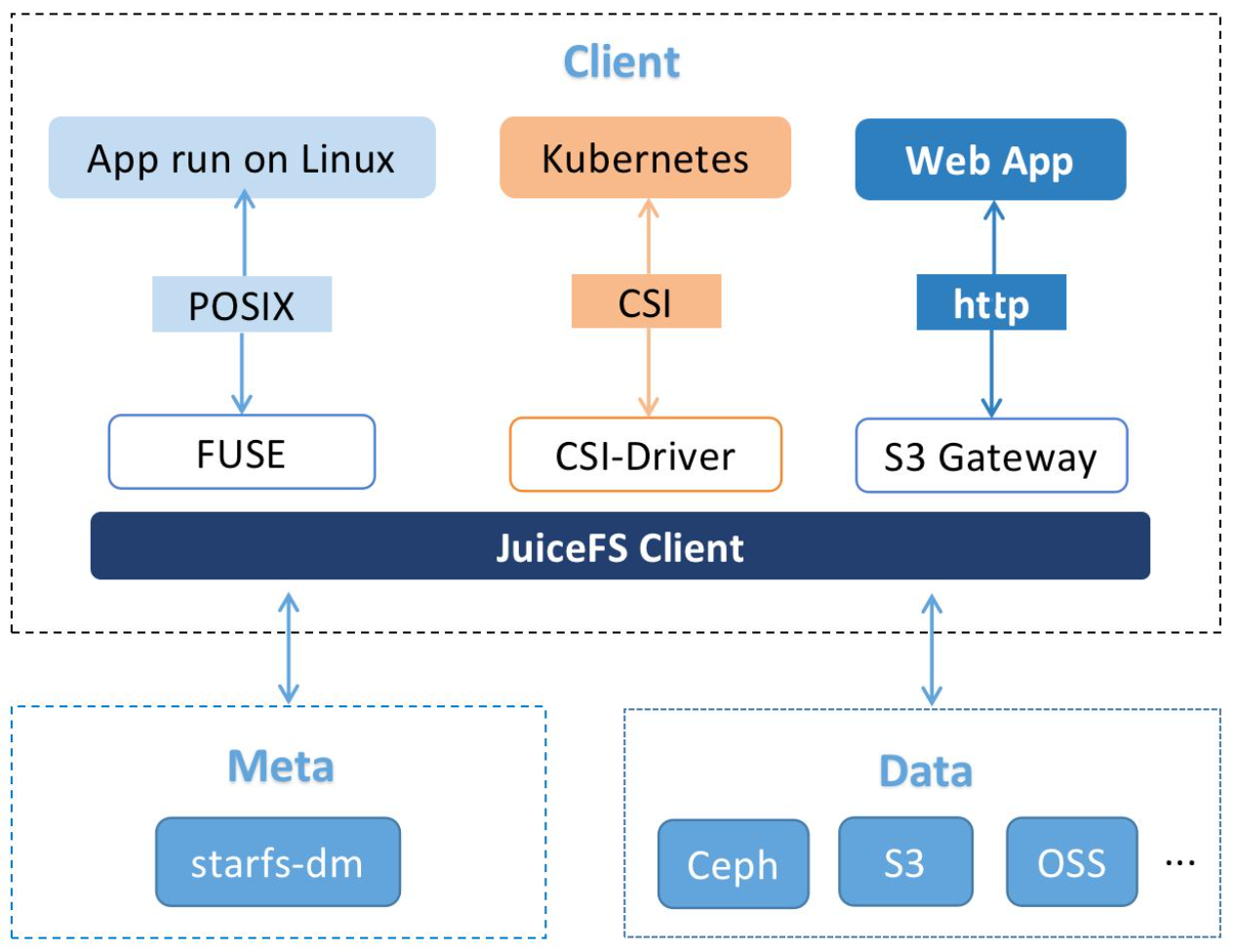
Xiaomi's JuiceFS architecture is similar to that of JuiceFS Community Edition. On the JuiceFS client side, we provide upper-layer protocol support and connect with our meta service and data service at the lower layer.
How we use JuiceFS at Xiaomi
We use JuiceFS in four scenarios: machine learning, persistent file storage, shared data access, and big data analytics. Currently, our most prominent area of business lies in machine learning, while we are actively exploring opportunities in big data and large model storage.
Our single cluster has now reached billions of files and petabytes of data, with throughput reaching several hundreds of Gbps.
In the past two years, we’ve formally integrated JuiceFS into our learning platform. Currently, it is mainly used to support autonomous driving training, certain mobile phone training, and next-generation speech training.
Last year, we extended our support to container platforms, launched public clusters, and provided container platform interfaces to meet various application needs. Subsequently, we integrated JuiceFS into the training application of Xiaoai Voice, Xiaomi Corporation's intelligent voice assistant. Previously, they used bare metal servers with SSDs to run NFS services. However, as data volumes continued to grow and the team expanded, they encountered difficulties in scaling and data management. Therefore, they decided to adopt our services last year.
This year, we’ve ventured into some new application areas, including migrating big data Iceberg to the cloud for performance verification and comparison. Additionally, concerning large model storage, we now support complete storage, including access to raw corpora, algorithm training, and storage of basic model files.
Exploration of cloud-based big data scenarios
In the performance verification of migrating big data Iceberg to the cloud and comparing it with similar products, JuiceFS excels in various I/O read/write scenarios, outperforming in some and being slightly slower in others. Overall, its performance can compete with that of public cloud products.
I've also learned that some other storage products, to some extent, have been inspired by JuiceFS in terms of data organization, management, and acceleration design.
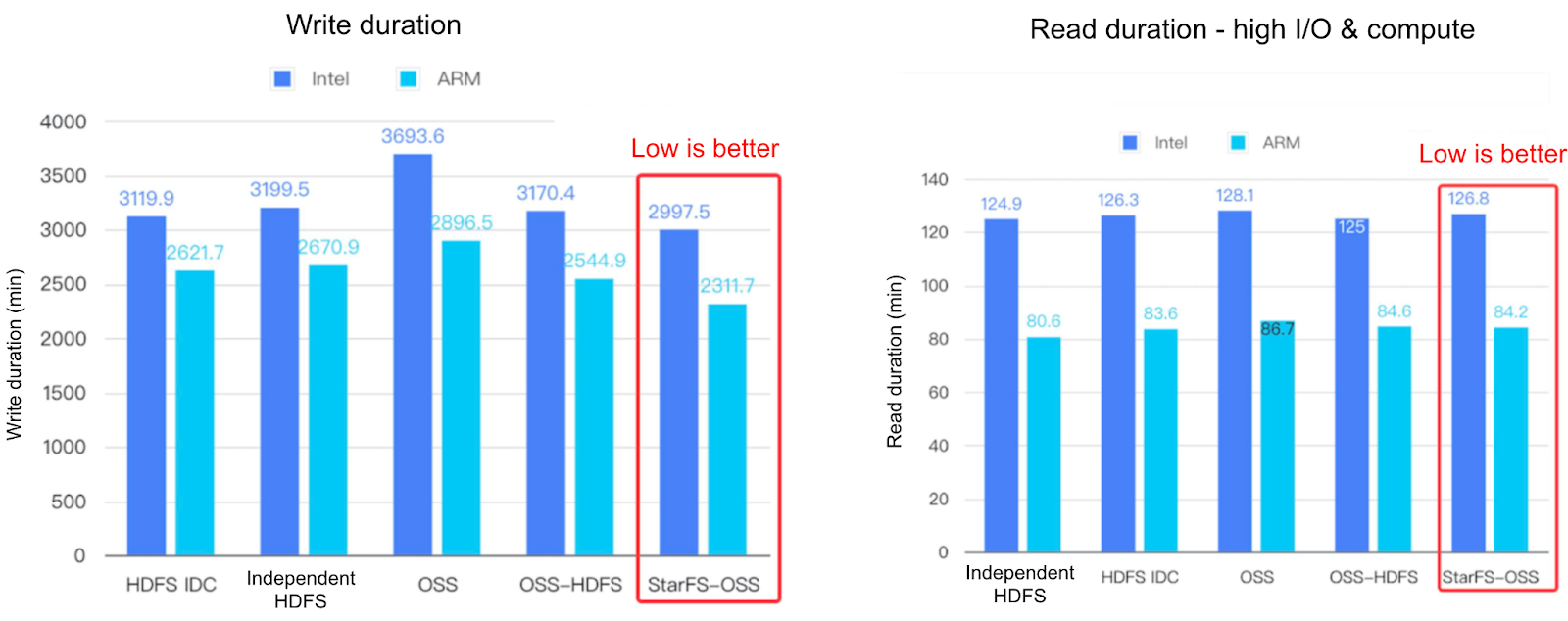
Application benefits in the speech training scenario
We have many application migrations to and utilization of JuiceFS file storage services. As an example, let's discuss the benefits brought to the application by migrating to JuiceFS in the speech training scenario:
- Capacity: Previously, speech group data was primarily stored on NFS. It often encountered issues where a storage machine would become full, causing users on that machine to be unable to write further. As training scales increased, both capacity expansion and management became inconvenient. The JuiceFS offered by the Cloud Platform-Cloud Storage Team theoretically better meets our requirements.
- Costs: JuiceFS has a lower cost per unit capacity compared to NFS. Currently, speech group data has been migrated from NFS+FDS to JuiceFS. This results in lower monthly costs per terabyte of storage capacity, calculated based on machine costs.
- Data safety: In the NFS configuration for speech, we used a combination of RAID 10 and RAIDO. Currently, we employ a three-replica storage mode on JuiceFS, which offers enhanced data safety.
- Concurrency: With NFS, users' I/O often concentrated on a particular storage node. Heavy I/O tasks by one user on a storage node would impact other users on the same node. However, JuiceFS distributes data across multiple nodes, resulting in less interference between users when multiple users on multiple machines access data concurrently, leading to a higher I/O ceiling.
Future plans
Cost optimization:
- Tiering: We’ll encourage more use of public cloud object storage to reduce data storage costs.
- IDC optimization: We've introduced high-density machine configurations to cut costs and optimized our storage methods, including the adoption of erasure coding storage and the segregation of small and large I/O operations.
- Metadata management: Our metadata currently uses an all-in-memory mode. For applications with a large number of small files, memory usage for metadata can be high and costly. To reduce processing costs, we need to support a DB mode. We no longer use all-in-memory storage but instead use a local RocksDB+SSD approach.
Performance enhancement:
- We’ll improve all-flash storage performance by adding support for RDMA and SPDK to reduce latency.
- Our GPU Direct Storage (GDS) will target AI large model scenarios, providing high-speed storage capabilities.
- We’ll optimize Meta transferring the proto protocol to reduce marshaling overhead and data transfer volume.
Feature enrichment:
- We’ll adapt to the latest features of JuiceFS Community Edition, such as the directory quota functionality.
- We’ll try to implement certain capabilities of JuiceFS Enterprise Edition, such as support for distributed caching and snapshots.
- We plan to implement the lifecycle management and QoS rate limiting features.
If you have any questions or would like to learn more details about our story, feel free to join discussions about JuiceFS on GitHub and the JuiceFS community on Slack.