挑战与痛点
- AI 作业管线(Pipeline)纷繁复杂、流程长,不同的计算、训练、应用框架有不同的数据访问方式,需要部署多套支持不同访问协议的存储。这样做会让数据分散在多套存储系统中,难于管理,加重维护负担,影响业务效率;
- I/O 性能会影响 GPU 利用率,进而影响到数据预处理、训练时的数据集读取、写 Checkpoint、模型加载等多个 AI 作业管线上的环节,这将直接影响成本和企业产品推向市场的时间;
- 一些模型(如视觉模型、多模态模型)的训练数据集会有几十亿级到几百亿级的小文件,LOSF(Lot of Small Files)一直是存储领域的挑战;
- 大多数存储系统性能与数据量或磁盘数成线性关系,为了支持不断增长的业务负载需扩容集群,但扩容又会带来复杂的运维工作且可能干扰现有业务。如何为 AI 作业提供高性能且能够弹性伸缩的存储方案?
- 在大规模 AI 模型训练中(如 LLM 模型训练),集群和数据规模的增长导致了数据访问压力增大,而传统 SAN 和 NAS 系统在支持数千乃至上万客户端的并发请求方面存在扩展性挑战;
- AI 模型训练对 GPU 算力需求巨大,因此多云、混合云已成为许多企业的标准配置,但直接从中心存储访问多云、混合云架构中不同位置的数据面临带宽和成本限制,且难以满足性能需求;
- 数据是 AI 业务的重要资产,常被多个团队使用。对于数据集、Checkpoint、日志等多类型数据的使用,管理需求涵盖权限设置、版本、容量限制等方面,而且还要与 Kubernetes 等环境集成。因此在存储系统选型时还需要考虑 ACL 控制、子目录挂载、Kubernetes 部署方式等多方面的挑战。
Why JuiceFS?
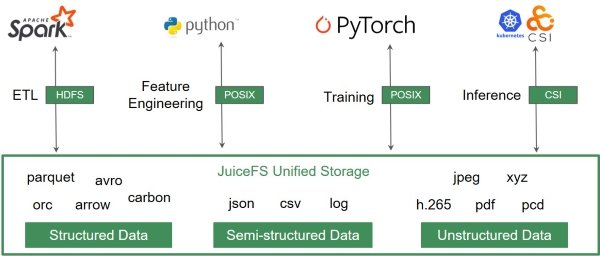
- JuiceFS 同时提供兼容 POSIX、HDFS、S3 的接口,可以作为 AI 作业管线的统一存储,减少多余的数据拷贝和迁移工作;
- JuiceFS 可为不同团队共享存储系统提供数据隔离和安全性保障:基于访问令牌(Token)的挂载和访问控制、Linux 文件权限(File Permission)、POSIX ACL、子目录挂载、容量与 Inode 配额、流量 QoS 等能力;
- JuiceFS 采用缓存、预读、并发读等策略来提升 I/O 效率。自研高性能元数据服务每秒可以承载上百万的请求、元数据服务请求的平均响应时间在毫秒级甚至百微秒级;
- 在模型训练这类读多写少的场景,通过 JuiceFS 多级缓存技术可加速数据读取,在 模型训练中 JuiceFS 的读吞吐可弹性扩展至数百 GB/s;
- JuiceFS 元数据服务和对象存储能满足数千至数万客户端的并发需求。JuiceFS 客户端的自动缓存功能在模型训练中可以显著降低元数据服务和对象存储的负载,进一步增强整体存储系统的承载能力;
- JuiceFS 的文件系统镜像特性为企业提供了高效的跨区域、跨云的数据存储、共享和同步能力;
- JuiceFS 企业版有针对高性能文件系统需求设计的高可用、全内存元数据服务,可以在线进行横向扩展,轻松管理百亿级文件。