1.什么是分布式文件系统?
分布式文件系统(Distributed File System,DFS)是一种计算机文件系统,它可以通过网络将不同计算机中的文件系统结合起来,使得用户访问和操作文件时,就像这些文件是存储在他们自己的本地计算机上一样。而实际上,这些文件可能存储在网络中的其他计算机上。用户无需关心或了解文件的实际存储位置和方式,分布式文件系统会自动处理这些复杂的过程。
分布式文件系统的设计目标主要是为了满足可扩展性、可靠性、高性能等需求:
- 可扩展性:分布式文件系统应当能够轻松地扩展,以支持更多的数据、用户和计算机。
- 可靠性:数据的持久性和防止数据丢失或损坏。可以通过数据冗余、备份和错误检测与纠正等技术来实现。
- 高性能:分布式文件系统应当能够提供高效的文件存取性能。这可以通过在网络中分布数据和请求来实现。
Google的GFS(Google File System)、Apache基金会的HDFS(Hadoop Distributed File System)等,是业界公认的知名分布式文件系统,它们在传统数据中心环境中有着广泛的应用。
然而,随着云计算的普及,企业的数据备份和存储趋势正在大规模向云端迁移。为了应对这一转变,JuiceFS作为一款面向云时代的分布式文件系统诞生了。其核心设计采用了基于对象存储的分布式文件存储架构。
2.什么是POSIX?
POSIX(Portable Operating System Interface,可移植操作系统接口)是由全球最大的专业技术组织 IEEE(Institute of Electrical and Electronics Engineers)定义的操作系统接口标准,旨在实现不同操作系统之间的高度兼容性。
该标准定义了许多核心接口,包括文件系统操作(如读写文件、创建删除目录等)、进程管理(如创建进程、线程、进程间通信等)、信号处理等。通过这些标准化接口,开发者可以编写在各种平台上行为一致的可移植程序。许多现代操作系统,如UNIX、Linux、macOS等,都支持POSIX标准。即这些程序可以在多种POSIX兼容的环境中运行,而无需进行大规模的修改。有了这套标准接口就可避免使用某个特定操作系统或硬件平台的特性。
一些分布式文件系统,如Hadoop HDFS,根据其应用场景,选择部分的POSIX兼容性。在JuiceFS的设计之初,为了能够支撑更多应用,采用了完全的POSIX标准,以便用户能够无缝地集成各类应用,减少了使用门槛和切换成本。
3.什么是对象存储? 与块存储、文件系统的区别
对象存储(Object Storage)是一种存储架构,以平面地址空间和独特标识符存储数据。
对象存储的理念和初步设计可以追溯到90年代中期的一系列研究,研究人员开始意识到传统的文件系统和块存储系统的在处理大规模、非结构化数据存在的一些局限。直到21世纪初,随着大数据和云计算的兴起,对象存储才真正开始在商业产品中得到应用。例如,Amazon在2006年推出的S3服务和Google2008年推出的Cloud Storage服务都是基于对象存储设计的。
对象存储系统将数据视为一个完整的对象,每个对象包含数据、元数据以及唯一标识符。对象之间没有固有的关系,每个对象都是相互独立的。因此这些对象在地址空间中的的结构是扁平的,而不是层次结构。
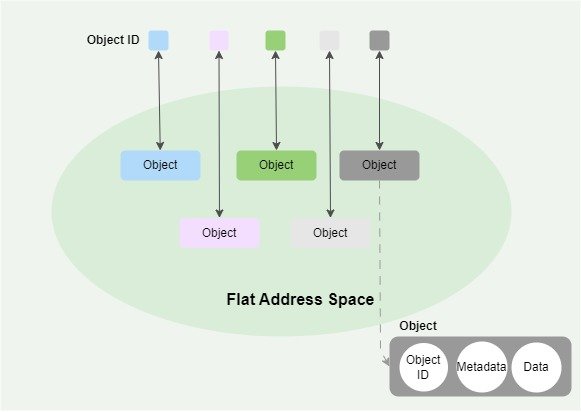
在文件系统这种层次结构中,数据被存储为文件,这些文件被组织在一种层次结构的目录中。文件和目录的路径定义了它们之间的关系,形成了树状结构。这种层次结构使得用户可以方便地浏览和管理文件,但当数据规模变得非常大时,目录结构可能会变得复杂,影响文件的检索效率。
对象存储扁平的结构使得它可以轻松地进行大规模扩展,因为新增对象不需要改变现有的结构或者路径。因此对象存储特别适合需要处理大规模非结构化数据,并且需要高效和检索性能的应用,如存储大规模的静态数据,如图像、视频等。
但是当涉及到修改对象内容时,对象存储的性能相对比较差。这是因为在对象存储系统的设计理念中,每个存储的对象都被视为一个不可更改的实体。一旦对象在系统中创建并存储,其内容将无法直接修改。如果需要改变对象的内容,需要创建一个新的对象(含有更新的数据),然后用新的对象替代原有对象。因为每次数据修改都需要创建和删除对象,这将消耗大量的时间和计算资源。因此,对于需要频繁修改的数据,例如数据库文件,日志文件等,使用对象存储就会带来性能问题。此外,由于对象存储系统通常采用了数据冗余和分布式存储的技术,数据的修改可能需要在多个存储节点之间同步,这也会带来额外的性能开销。
因此,对象存储系统通常不适用于以下场景:
- 高频率的数据修改:例如数据库文件,日志文件等。
- 低延迟的数据访问:例如在线交易处理(OLTP)系统,实时分析等。
- 文件级操作:例如需要文件锁,文件版本控制等功能的应用。
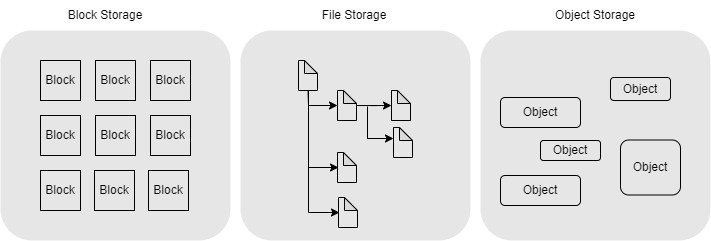
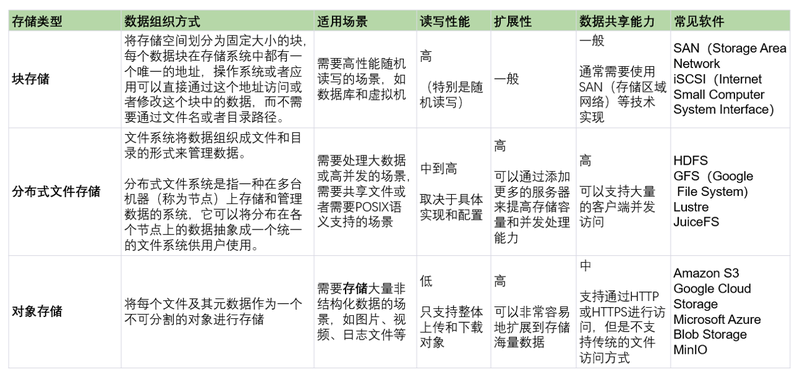
对象存储、块存储和文件系统是三种常见的数据存储方式,它们在底层硬件上都是使用磁盘或者固态硬盘存储数据,不同的是它们对数据的组织方式和访问方式。
4.什么是数据持久化?
数据持久化是指将数据在短期或临时存储之后,长期保存在存储介质中,以确保数据在计算机系统或应用程序关闭后仍然可用。
数据持久化在许多场景中都是必要的,以下是一些常见的场景:
- 应用程序数据存储:许多应用程序需要持久化存储数据,以便在应用程序关闭后或系统重启后能够恢复数据状态。这包括用户配置、应用程序状态、用户生成的内容等。
- 数据库系统:大多数企业和组织使用数据库系统来存储和管理关键业务数据。数据库系统提供持久化存储、高级查询和事务处理等功能,确保数据的完整性和可靠性。
- 日志记录:许多系统和应用程序需要将日志数据持久化存储,以便进行故障排除、性能分析和安全审计等目的。日志记录是对系统状态和事件的持续记录,通常包括错误日志、访问日志、操作日志等。
- 大数据和分析:在大数据和分析领域,需要对海量数据进行持久化存储,以便后续处理和分析。这些数据可能来自多个源头,包括传感器、日志、社交媒体等,持久化存储可以确保数据可用性和可回溯性。
- 安全和合规性要求:许多行业和组织有严格的安全和合规性要求,需要将敏感数据进行持久化存储并采取适当的保护措施。这包括金融机构、医疗保健、电子商务等领域。
- 数据备份和灾难恢复:数据持久化也是进行数据备份和灾难恢复的基础。通过定期备份数据并将其持久化存储在安全的位置,可以保护数据免受硬件故障、自然灾害、人为错误等的影响,并能够在需要时进行恢复。
以下为常见的数据持久化的实现方式以及每种方法的特点:
5.什么是共享存储?
共享存储用于多个计算节点(如服务器或计算机)之间共享数据存储资源。它提供了一个集中管理的存储池,使多个节点可以同时访问和共享存储数据。
在共享存储中,存储资源可以是物理存储设备(如磁盘阵列、网络附加存储等)或逻辑存储(如虚拟存储卷、共享文件系统等)。这些存储资源通过专用的存储网络或高速连接与计算节点连接在一起。
以下是一些常见的共享存储应用场景:
- 大规模数据处理,如数据分析、机器学习和人工智能。
- 虚拟化环境,用于存储虚拟机的磁盘映像文件和配置数据。
- 高可用性和容错性要求的环境,实现数据冗余和故障切换。
- 分布式系统和集群环境,存储和共享共享资源。
- 数据库系统,实现多个数据库实例之间的数据共享和访问。
- 文件共享和协作,团队合作、文档管理和文件共享。
- 视频编辑和媒体处理,多个编辑工作站共享和处理视频素材。
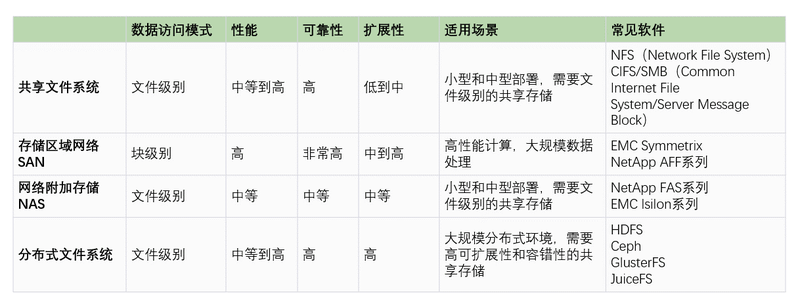
有多种方法可以实现共享存储,以下是几种常见的方法和他们的特性:
6. 什么是大数据存储?
大数据存储是指用于存储和管理大规模数据集的技术和方法。随着数据的不断增长和多样化,传统的数据存储方案往往无法满足大数据处理的需求。
大数据存储通常需要满足以下特点:
- 高容量:大数据存储需要能够处理和存储海量的数据,包括结构化数据、半结构化数据和非结构化数据。
- 高性能:大数据处理通常需要快速的读写速度和查询响应时间,以满足实时或近实时的数据分析和处理需求。
- 可扩展性:大数据存储方案需要支持横向扩展,以便随着数据量的增长而扩展存储容量和处理能力。
- 弹性和容错性:大数据存储应具备容错和数据冗余的能力,以确保数据的可靠性和可用性。
- 多样性数据支持:大数据存储需要能够处理各种类型的数据,包括结构化、半结构化和非结构化数据。
常见的大数据存储技术包括分布式文件系统(如Hadoop的HDFS)、分布式数据库(如Apache Cassandra、Apache HBase)、对象存储(如Amazon S3、Google Cloud Storage)、列式数据库(如Apache Parquet)等。这些技术和方案提供了高容量、高性能和可扩展性,适用于大规模数据存储和处理的场景。