







JuiceFS 非常适合用来做 MySQL 物理备份,具体使用参考我们的官方文档[1]。最近有个客户在测试时反馈,备份验证的数据准备(xtrabackup --prepare)过程非常慢。我们借助 JuiceFS 提供的性能分析工具做了分析,快速发现性能瓶颈,通过不断调整 XtraBackup 的参数和 JuiceFS 的挂载参数,在一个小时内将时间缩短到原先的 1/10。本文将我们性能分析和优化的过程记录分享下来,给大家分析和优化 IO 性能提供参考。
0. 数据准备
我们通过 SysBench[2] 工具生成一个大小 11GiB 左右的单表数据库,数据库表的 partition 设置成 10。为了模拟一个正常的数据库读写场景,通过 SysBench 以秒 50 个请求的压力访问数据库,在该压力下数据库对数据盘造成的写数据在 8~10MiB/s 范围内。通过下列命令将数据库备份到 JuiceFS 上。
# xtrabackup --backup --target-dir=/jfs/base/为了保证每次数据准备操作的数据完全一样,使用 JuiceFS 的快照(snapshot)功能基于 /jfs/base 目录生成快照 /jfs/base_snapshot/。每一次操作前都会将前一次数据准备操作过的数据删掉重新生成一个新的快照。
1. 使用默认参数
# ./juicefs mount volume-demoz /jfs
# time xtrabackup --prepare --apply-log-only --target-dir=/jfs/base_snapshot执行总耗时62秒。
JuiceFS支持导出操作日志 oplog,并能对 oplog 进行可视化展示。在执行 xtrabackup --prepare操作之前我们新开一个终端连接到该服务器,在命令行输入
# cat /jfs/.oplog > oplog.txt开始搜集 oplog 日志,然后执行 xtrabackup --prepare 操作,操作结束后将 oplog.txt 下载到本地,上传到 JuiceFS 提供的 oplog 分析页面:https://juicefs.com/oplog/。
我们将 oplog 进行可视化展示。
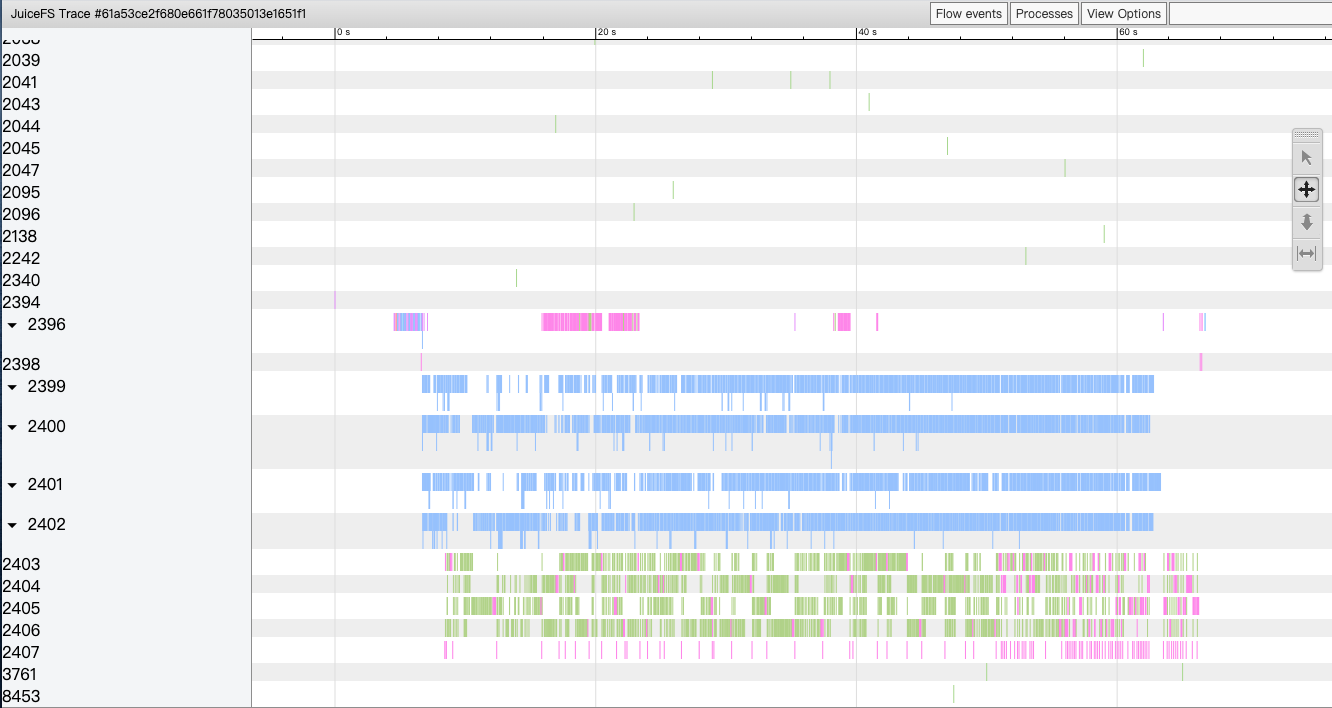
这里先大致介绍下这个图中各种元素含义。我们的一条 oplog 中包含了时间戳,线程 ID,文件系统操作函数(read, write, fsync, flush 等),操作持续的时间等。左侧数字表示线程 ID,横轴表示时间,不同类型操作用不同颜色标记。
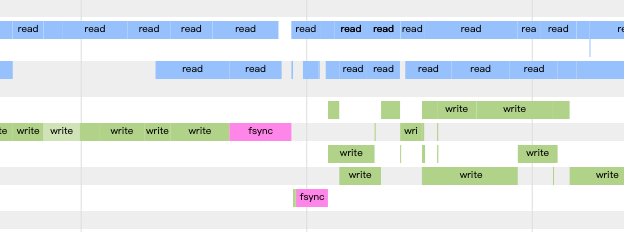
我们把局部图像放大,不同颜色代表不同类型的操作就一目了然。
排除掉与本次操作无关的几个线程。在数据准备过程中有 4 个线程负责读,5 个线程负责写数据,读写在时间上都是重叠的。
2. 增大 XtraBackup 的内存缓冲区
参考 XtraBackup 官方文档[3],数据准备是使用内嵌的 InnoDB 在备份数据集上执行故障修复(crash recovery)的过程。
使用 --use-memory[4] 选项增大内嵌 InnoDB 的内存缓冲区大小,默认 100MB,我们增大到 4GB。
# time xtrabackup --prepare --use-memory=4G --apply-log-only --target-dir=/jfs/base_snapshot执行时间降到了33秒。
将 oplog 可视化展示。
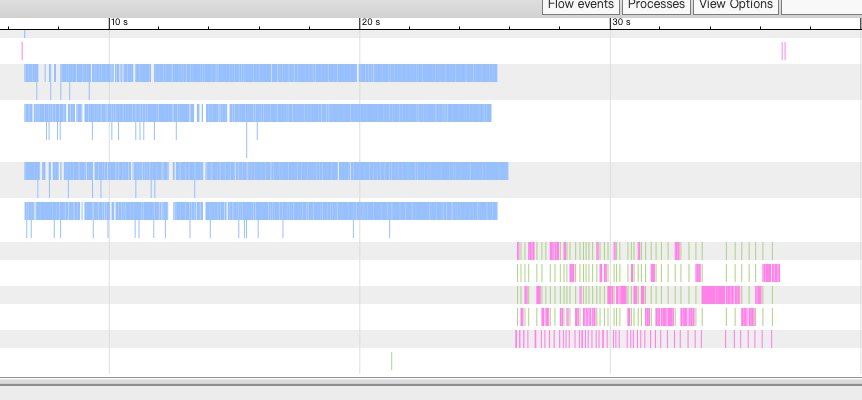
可以看到读写不重叠了 ,将数据读到内存处理完成后写入文件系统。
3. 增大 XtraBackup 读线程数
通过增大缓冲区将时间缩短了一半,整个读的过程耗时依然比较明显。我们看到每个读线程基本都是跑满的状态,我们尝试增加更多的读线程。
# time xtrabackup --prepare --use-memory=4G --innodb-file-io-threads=16 --innodb-read-io-threads=16 --apply-log-only --target-dir=/jfs/base_snapshot执行时间降到了23秒,将 oplog 可视化展示。
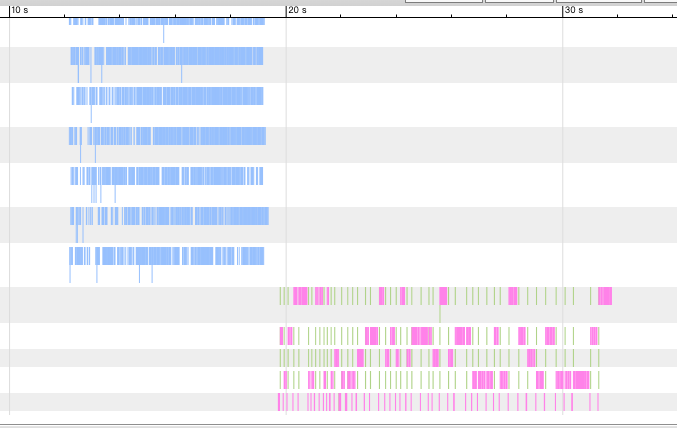
读线程已经增加到了 16 个(默认 4 个),读操作降到 7 秒左右。
4. JuiceFS 启用异步写
上一步我们极大的优化了读操作时间,现在写过程消耗的时间就比较明显了。通过分析 oplog,发现写操作中fsync是不能并行的,因此增大写线程数并不能提升写的效率,在实际操作过程中我们也通过增大写线程数验证了这一点,这里就不赘述了。分析 oplog 对同一个文件(相同文件描述符)的写操作的参数(偏移,写数据大小),发现有大量的随机写操作,我们可以在挂载 JuiceFS 时启用 --writeback 选项,写数据时先写本地盘,再异步写到对象存储。
# ./juicefs mount --writeback volume-demoz /jfs
# time xtrabackup --prepare --use-memory=4G --innodb-file-io-threads=16 --innodb-read-io-threads=16 --apply-log-only --target-dir=/jfs/base_snapshot时间降到了 11.8 秒,将 oplog 可视化展示。
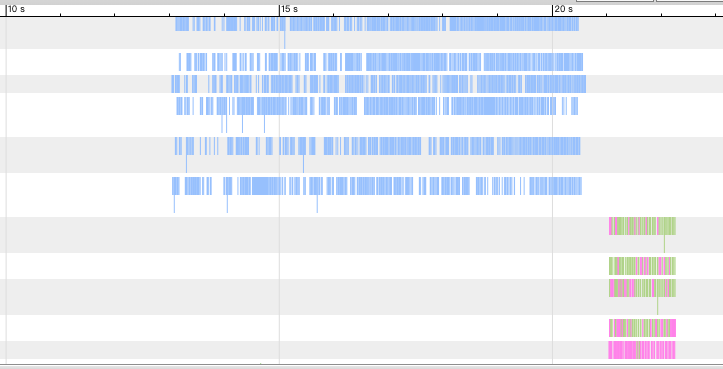
写过程已经降到 1.5 秒左右。
我们看到读线程读操作依然比较密集,我们尝试持续增加读线程数,InnoDB 读线程数最大为 64,我们直接调成 64。
# time xtrabackup --prepare --use-memory=4G --innodb-file-io-threads=64 --innodb-read-io-threads=64 --apply-log-only --target-dir=/jfs/base_snapshot执行时间 11.2 秒,相比之前基本没变化,将 oplog 可视化展示。
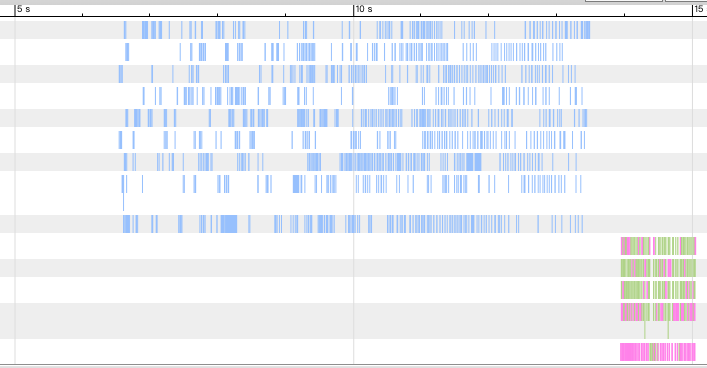
我们看到,读线程读操作已经比较稀疏了,应该是线程读的数据之间有依赖关系,导致不能完全并行化,已经不能通过提升线程数压缩读过程的时间了。
5. 增大 JuiceFS 的磁盘缓存
在上一步中,我们通过提升读线程数来提升读过程的效率已经到顶了,只能通过降低读数据的延迟来减少读过程时间。
JuiceFS 在读操作处理上提供了预读和缓存加速能力,我们接下来尝试通过增大 JuiceFS 的本地缓存来降低读操作的延迟。
将 JuiceFS 的本地缓存由高效云盘换成 SSD 云盘,并将缓存大小由 1G 改成 10G。
# ./juicefs mount --writeback volume-demoz --cache-size=10000 --cache-dir=/data/jfsCache /jfs
# time xtrabackup --prepare --use-memory=4G --innodb-file-io-threads=64 --innodb-read-io-threads=64 --apply-log-only --target-dir=/jfs/base_snapshot执行时间降到了 6.9 秒,将 oplog 可视化展示。
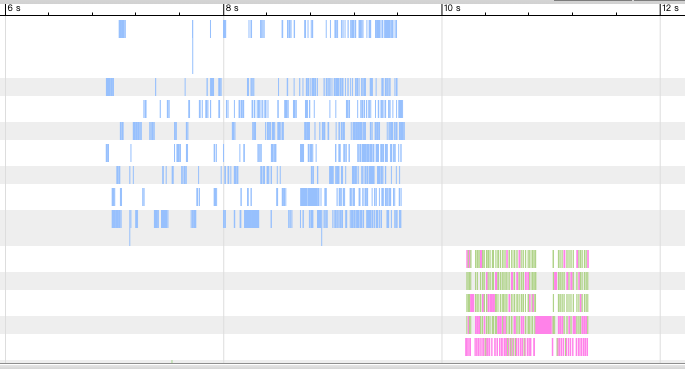
通过提升缓存性能和增大缓存空间进一步减少了读操作耗时。
到此我们总结一下,我们通过分析 oplog,不断寻找可以优化的点,将整个数据准备过程一步步从 62 秒降到 6.9 秒,效果通过下图更直观的展示。
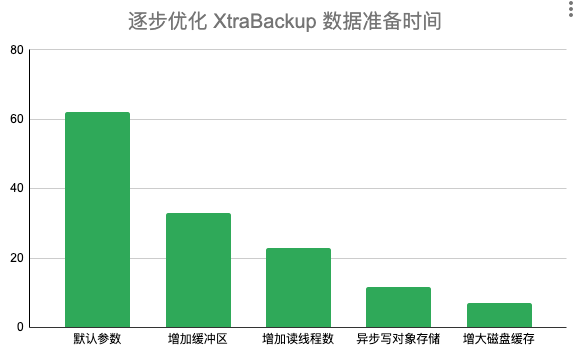
6. 增大数据库数据量
以上的操作都是针对 11G 这样一个比较小的数据集不断调整参数进行优化得到一个很好的结果。作为对比,我们以同样的方式生成一个 115G 左右的 partition 为10的单表数据库。在 SysBench 持续每秒 50 个请求情况下,执行备份操作。
# time xtrabackup --prepare --use-memory=4G --innodb-file-io-threads=64 --innodb-read-io-threads=64 --apply-log-only --target-dir=/jfs/base_snapshot这个过程耗时 74 秒,将 oplog 可视化展示。
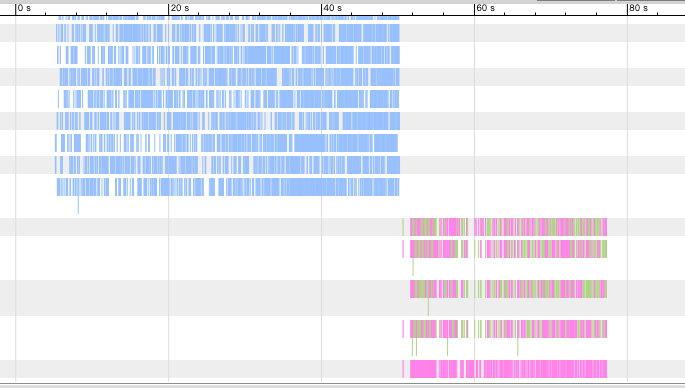
我们看到,读和写还是分开的。
在数据量增大10倍左右,相应的准备时间也增大到10倍。这是因为备份(xtrabackup --backup)过程所需的时间扩大到 10 倍,在 SysBench 对数据库压力不变的情况下,备份过程中产生的 xtrabackup_logfile 也是原先的 10 倍。数据准备是要把 xtrabackup_logfile 中的所有数据更新合并到数据文件中,可见即使数据规模增大了 10 倍,但更新单条日志的时间基本不变。从上图也可以验证这一点,数据规模增大后,准备过程仍然是分成了读数据和写数据这两个明显的过程,说明设定的 4GB 的缓冲区大小仍然是够用的,整个过程仍然可以在内存中完成然后更新到文件系统。
总结
我们使用 SysBench 这个相对简单的工具构造初始数据,持续给数据库一定数据更新的压力模拟数据备份时数据库运行场景。使用 JuiceFS 的 oplog 来观察 XtraBackup 在数据准备过程中访问备份数据的读写特点,调整 XtraBackup 和 JuiceFS 的参数来不断优化数据准备过程的效率。
在实际生产场景中,情况比我们 SysBench 模拟要复杂得多,我们上面的线性关系不一定严格成立,但是我们通过分析 oplog 快速发现可以优化的点,进而不断调整 XtraBackup 和 JuiceFS 的缓存和并发的思路是通用的。
整个调参过程耗时 1 小时左右,oplog 分析工具在这个过程中发挥了很大的作用,帮助我们快速定位系统性能瓶颈,从而针对性地调整参数做优化,也希望这个 oplog 分析功能也能帮助大家快速定位和分析遇到的性能问题。
参考文档
[1]: 基于 JuiceFS 的 MySQL 备份、验证和恢复方案: https://juicefs.com/docs/zh/backup_mysql_in_juicefs.html
[2]: SysBench: https://dev.mysql.com/downloads/benchmarks.html
[3]: XtraBackup全量备份: https://www.percona.com/doc/percona-xtrabackup/2.4/backup_scenarios/full_backup.html
[4]: XtraBackup命令行选项: https://www.percona.com/doc/percona-xtrabackup/2.4/xtrabackup_bin/xbk_option_reference.html


